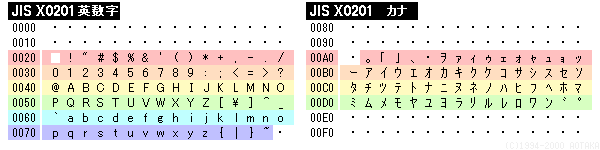
 ※7ビット符号化方式では左の英数記号がなく、代わりにカナが配置されています。 ※半角・全角という区別はパソコンの問題で、JIS X0201規格票では規定していません(JIS規格票には正方形状の字体で掲載されています) |
| Copyright(c)AOTAKA 1995-2003 - www.aotaka.jp |
文字コードは日本では
「7ビット及び8ビットの情報交換用符号化文字集合」(JIS X0201:1997)
「7ビット及び8ビットの2バイト情報交換用符号化漢字集合」(JIS X0208:1997)
などのように称しています。情報交換用符号自体は単なる0・1の羅列であり、真に重要なのは○○コードを使うという通信する両者の合意です。送信者と受信者で合意がない場合には、暦(JIS:4E71)を乱(UNICODE:4E71)と間違えてしまうようなことが起こるかもしれません。
実際に日本人が遭遇しやすい問題は2つ有り、一つは明らかな文字化けという問題ですが、こちらは人間の目に明らかなため対処法さえ分かれば軽微な問題といえます。しかしもう一つは「旧JIS(1983年以前)と新JIS(1983年以後)は厳密には別物」だという問題は非常に厄介です。
なぜ日本工業規格(JIS)ともあろう物がこのようなことを許してしまったのかは別にしても、文字コードとしては論外です。本来は100%別物として扱われるべき改正です。(Unicodeでもやらかしちゃっていますが…)
この問題の例を挙げると、有名な諫早湾の「諫」は言に柬ですが、別のパソコンで見れば言に東と書いて「諌早湾」(旧JISの表示系で見れば、こちらの方が正しく見えます)と見えてしまうかもしれません。諫早湾などは本来の字を知っている人間にしか分からないし、こんな細かい間違いを画面上で探せなんて言われても気がつく可能性は低いでしょう。このまま言東な本でも出版されてしまったら非常にガッカリです。
コードが世界に一つならば問題はありませんが、文字コードは電子機器の発達や各々の思惑に伴い、数々の文字コードが登場し、未だに進化の途上にあることを伺わせます。ここでは日本語をサポートする文字コードを中心に説明します。
一般に文字集合と符号化文字集合は、文字コードと一括りにされていますが、意味においては重大な違いがあります。文字集合は文字を集めてきて表などに整理した状態であり、JIS X0208がそれに当たります。一方実際に使用することを想定し、コンピューターや通信回線上で使うための符号化(コード化)をしてある物を符号化文字集合と呼び、JUNETコード(ISO 2022-JPとして国際規格になっている)、Shift JIS、EUC、UCS、Unicodeなどがそれに当たります。
簡単に説明するとすれば、文字を集めた状態を「文字集合…character sets」、具体的な使用方法までを規定した状態を「符号化文字集合…corded character sets」と考えれば良いでしょう。また「文字セット」という言葉は「文字集合」と同じ意味です。
ISOは国際的な標準規格を制定するための団体です。一方JISは日本国内の工業用標準規格です。米国合衆国のANSI、中国のGB(国家標準)や大韓民国のKSなども、それぞれの国の標準規格です。
JISにはISOと同一と言ってもよい様な規格が多く存在しますが、これはISOで決まった物は速やかに国内標準とするという方針に基づき、日本工業規格に翻訳してしまうからです。国内初の情報交換用符号に関する規格C6220(現X0201)も元々はISO R646(Rは規格案の意味)の丸写しにカナを独自拡張したものです。
世界初の標準的文字セットとなるASCIIの制定前、そして後もメインフレームなどでは機種独自のコードを採用していました。IBMならばEBCDIC、富士通はJEF、日立はKEIS・EBCDIK、…。IBMのコードということでEBCDIC(Extended Binary Coded Decimal Interchange Code)は有名ですが、アルファベットが8ビットでしか扱えない、0x80以上の領域にあり、かつ飛び飛びになっているなど、大変使いにくいコードであったようです。
American Standard Code for Information Interchange(情報交換用米国標準コード)の頭文字を取ったもので「アスキー」と発音します。1963年以前は機械ごとに独自の文字コードが運用され、他の機械との情報交換を行うことが非常に不便であったために、外部との通信時だけでも規格統一しようという目的で作られた米国内規格です。
当時のコンピューターは英語が標準で使われていたことや、ASCII自体の設計が優れていたために後にコンピューターの外部・内部コードを問わずに標準として定着しました。
7ビット(128符号)のうち、コントロールキャラクター(制御用符号、十進数表記で0~31)と空白(32)、削除符号(127)を除く、94文字がグラフィックキャラクター、つまり文字です。これでは「”」が一つしかないなど、通常の英文を正確に表記することすらままなりませんが、1960年代のコンピューターでは7ビットですら負担が重すぎるとアルファベットの小文字すら省いた6ビット=64符号の規格案も存在し、当時は計算結果さえ分かればよいと強く思われていたために6ビット方式が優勢なほどでした。現在では7ビットASCIIしか残っていません。
ちなみにアオタカが1980年に触った当時60万円のマイコン(パーソナルコンピューターは1980年代に一般化した用語です)AppleⅡPlusではアルファベットの小文字は装備されていませんでした。
ASCII(US-ASCIIとも表記されます)は米国内規格ですが、これを国際規格にしようとしたのがISO 646です。この符号化文字集合は、ASCII文字セットとほぼ同じ(2000年現在は同一)である標準モデルIRVを定め、そのIRVを元に各国の国情に合わせて0x23・0x24・0x40・0x5B~0x5E・0x60・0x7B~0x7Eの12文字は他の文字と入れ替えてもよいということになっています。
| コード | 0x23 | 0x24 | 0x40 | 0x5B | 0x5C | 0x5D | 0x5E | 0x60 | 0x7B | 0x7C | 0x7D | 0x7E |
| IRV (今はASCIIと同じ) |
# | $ | @ | [ | \ | ] | ^ | ` | { | | | } | ~ |
| JIS (規格票の字形) |
# | $ | @ | [ | ¥ | ] | ^ | ` | { | | | } | - |
| NEC (PC-9800、EPSON PC) |
# | $ | @ | [ | ¥ | ] | ^ | (`) | { | | | |
} | ~ |
日本では、ISO 646 IRVとの違いが0x5C「¥」だけで、さらに独自に8ビットへ拡張したJIS X0201が一般に利用されています。(2000年現在のパソコンではさらに同じ領域にShift JISを混在させて使っています)
ASCIIは94しか文字を持てませんが英語以外の国で使う時には、当然自国の文字が不足します。そこでISOでは12文字を国情に合わせて変更して良いことにしました。しかしこのような方法は、ASCIIとの互換性が無くなるばかりで不便なことから廃れ、現在ではASCIIとほぼ同等のIRV(2000年現在はASCIIと等しくなっています)しか利用されていません。従来、ISO 646を使っていた国のほとんどがISO 8859に移行しています。
ISO 646の問題点としては、日本国内では¥(円記号)が異なり、チルダはオーバーラインと表現(ただし字形の揺れ程度)されていますが実用上は大きな問題にはなりません。しかし入れ替え可能な文字数が多くなれば当然それだけ各国の互換性が維持できなくなるばかりか、国によっては更なる悲劇を生んでしまいました。例えばプログラム言語のC言語では#[]{}\^|~を多用しますが、これらが文字に置き換えられてしまった場合は、仕方無しにANSIの標準規格に従ってトライグラフという非常に面倒なエスケープシーケンスのような文字を使わなければならなくなり、視認性はすこぶる悪くなります。国内では\が¥に化けるために「地獄の沙汰も金次第」という言葉が生まれたくらいですが(うそ)、括弧類が全てアルファベットに化けまくりな国では洒落にならないために日本以外では廃れました。
ASCIIは規格案の段階から既にISOによる国際標準化の動きがあり、ISO R646としてISO案が登場しました。これを受け日本でも国内標準化を急ぎ、1969年にJIS C6220-1969『情報交換用符号』を制定します。これにはASCIIで紛糾した6ビット、7ビット双方の規格が書かれていました。当時の技術水準では本気で両方がISOに昇格すると思っていたとしても致し方ありませんが、ISO 646制定後に改正されたJIS C6220-1976では6ビット方式が削除されています。
JIS C6220とASCIIやISO 646の最も異なる点はカタカナを扱える点です。コードとしては左(0x00~0x7F)はISO 646を、ほぼ丸飲みする形で踏襲しており、左半分での違いは0x5Cのバックスラッシュを円記号に置き換え、0x7Dのチルダがオーバースコアと表現された程度です。
なおチルダとオーバーラインの問題ですが、JIS X0201-1997附属書2で、送信者と受信者の間で明示的な合意がある場合は「チルダと同じ字形」をオーバーラインとしてよいことが追記されました。これはASCIIやISO 646が歴史的に「TILDE」と「OVER LINE」を別な文字と見なしていなかった歴史背景に基づく現実を明文化したものです。
一方ISO 646やASCIIには存在しない右半分(0x80~0xFF)では左半分の制御符号部分を避ける形で0xA1~0xDFにカナを配置する(いわゆるJIS8)という手法で巧みにカナを埋め込んでいます。7ビットしか扱えない環境のためには、ASCIIの制御記号のみを踏襲し0x21~0x5Fにカナを配置する方法(JIS7)も規定しています。これらは単独の規格として成立することはもちろん、ISO 2022と整合性の取れる仕組みとなっています。
※7ビット符号化方式では左の英数記号がなく、代わりにカナが配置されています。 ※半角・全角という区別はパソコンの問題で、JIS X0201規格票では規定していません(JIS規格票には正方形状の字体で掲載されています) |
ASCIIでは128符号のうち94文字が表せますが、ISO 2022では制御符号を用いて様々な文字コードを次々と切り替えていくことで混在させることができるようにするための規格です。94n集合(n=1の例としてはASCIIなど、n=2はJUNETコードなど)や96n集合(n=1はISO 8859-1の右半分)の文字集合を扱うことができます。日本の文字集合が94区94点で構成されるのもこれに合わせるためです。(ただしJIS X0208は第四次規格に至るまで、符号化の方法に触れてもいませんでした)
日本語のWEBページやメールなどでお馴染みのISO 2022-JPは、使用できる文字集合をASCII、JIS
X0201の英数、JIS C6226-1978、JIS X0208-1983のみにしたISO 2022簡略版(サブセット)です。
またJIS X0201はそれのみで完結しているコードではありますが、他方ISO 2022の一部としても規定されています。
日本では一足先にJIS C6220(現X0201)が制定されましたが、英語圏以外の諸外国でも自国の文字とASCIIとの共存を求める声が高まるにつれ、7ビット128符号から、8ビット(通信では1オクテットといいます)の体制に移行しました。新たに確保した0x80~0xFFの128符号についても文字を埋めこんだ8ビット文字セットの出現です。特に自国の文字数がそれほど多くない欧州などではASCII部分はそのままに、自国の数十文字を追加して使いたい場合に一番便利な方法でした。
実用上はASCIIの制御符号部分の影といえる0x80~0x9Fを除く96符号、または空白・削除(0xA0、0xFF)の影も避けた94符号の余裕ができました。そこにアクセント記号付きの文字を用いる欧州言語、キリル文字(キリール文字)、アラビア文字などを各国がそれぞれ勝手に配置した規格を使用するようになります。
そのような状況を受け、各国でローカライズされた8ビット符号化文字集合をISOが後追い承認的に、1987~1989年にかけて定義しました。これがISO 8859です。ISO 8859にはパート1からパート9までの9種類が規格化され(現在はもっと増えているかも…)、それぞれラテン系文字、キリル文字(キリール文字)、アラビア文字などが扱えるようになっていますが、実際に使用されるのはほとんどがパート1として定義されているLatin-1(ISO 8859-1)のみです。ちなみに日本のJIS X0201はISO 8859に申請していないのか、同等の物が存在しません。
インターネットでは8ビット目が1になる(0x80以降の)符号を流すことは本来あまり好ましくはありませんが、ヨーロッパのWWWなどでは、ISO 8859を使ってるページが多く見られます。これらの地域やShift_JISやEUC-JPを使う日本では現在8ビットに対応したコンピューターばかりですので、特に問題にはなりません。まあMicrosoftの様にメールのMIMEヘッダーに8ビットコードを入れるという無茶苦茶なソフト(MIMEはデータを7ビットにコード化するための手段です)ですら流通した時もありましたしね(笑)
| ●全角文字・半角文字とは | |
| 全角文字・半角文字という言葉は聞いたことがあると思いますが、これは文字コードの話をしているときには、的を射た用語ではありません。プロポーショナル表示が全盛の今になっては的をかすめるどころか大外れです。 いわゆる では何故、このような妙な表現が文字コードの問題で まるで正式用語のように語られるのでしょうか。 その昔、米国人が作ったコンピューターは英語を表示していましたが、この時たまたま、文字大きさは縦2に対して横1の比率だったのです。ASCIIで使う英・数・記号が綺麗に見え、画面上での位置を計算するのも楽だったので、この比率に落ち着いたのでしょう。 時代が進み、コンピュータの性能が上がれば当然、漢字が表示できるコンピューターが作られるようになりますが、漢字が縦長では当然妙な表示になってしまうので、自然に見える1:1の比率で作ることに落ち着きました。都合の良いことにこれならば英数2文字分の場所に収まり、しかも文字コードの大きさ(2バイト)と画面上の大きさ(2字分)の相関関係もバッチリ。 さてこの英数の幅が漢字に対して半分ということだけならば、全角・半角という言葉をこれほど使うこともなかったのでしょうが、JIS X0208には漢字に混じってASCIIと全く同じ英・数・記号も含まれていました。さてX0208の 今では画面表示でも印刷でもプロポーショナルフォントが普及し、等幅フォントを使用するのはもっぱら電子メールやネットニュースを読み書きするときくらいになりました。それでも全角・半角と言う曖昧な表現が主流で、2バイトの |
|
日本国内では将来の情報交換用漢字コードを決める作業は、情報処理学規格委員会で1969年に開始されましたが、当時は国語学者などを登用していたために、議論ばかりが白熱し、規格を決めるどころの話ではなかったようです。
そこで、それらの学者肌の人間を使うのは止めて、極めて事務的に漢字表の策定作業を行うことを目的にしたワーキンググループが結成され、1978年に最初の漢字文字セットを完成させました。
この規格では文字を非漢字・第一水準漢字・第二水準漢字に分別しました。この構造は後に制定される中国GB2312-80・大韓民国KSC5601-1987にも応用され、これらの規格では(長音記号を除く)平仮名・カタカナまで丸ごと同じ場所に収まっているほど似ています。ちなみに韓国では第一水準の部分にハングルの(代表的な)完成字形が入っています。
JIS C6226(現X0208)は、ある方法により一般に使用頻度や存在価値の高いと思われる漢字を抽出したものです。それを適当な分類方法(記号類・第一水準漢字・第二水準漢字)で分類し、さらに法則(第一水準は音引き、第二水準は部首順)により並べてたものを、94×94の表に並べていった物です。この表では縦横に「区」と「点」が割り振られており、その座標(区点)を指定することで文字が特定できます。
しかし残念ながら表そのものではコンピューターで使うことはできません。なぜなら実際に使用するときの約束事が決まっていないからです。(結局JISでは実際の使用法までを自ら定めることはありませんでした。)
| 文字種 | X0208(C6226) | X0212 | X0213:2000 | ||||||||||||
| 1978 | 1983 | 1990 | 1990 | 実装水準3 | 実装水準4 | ||||||||||
| 非 漢 字 |
平仮名 | 83 | - | 第三水準枠内に 拡張された非漢字
|
|||||||||||
| カタカナ | 86 | - | |||||||||||||
| 数字 | 10 | - | |||||||||||||
| 英字 | 52 | - | |||||||||||||
| 特殊記号 | 108 | 147 | - | ||||||||||||
| ギリシャ文字 | 48 | - | |||||||||||||
| ロシア文字 | 66 | - | |||||||||||||
| 罫線素片 | 0 | 32 | - | ||||||||||||
| 非漢字小計 | 453 | 524 | 266 | ○ | ○ | ||||||||||
| 漢 字 |
第一水準漢字 | 2965 | - | ○ | ○ | ||||||||||
| 第二水準漢字 | 3384 | 3388 | 3390 | - | ○ | ○ | |||||||||
| 補助漢字 | - | 5801 | - | - | |||||||||||
| 第三水準漢字 (第一面への追加) |
- | - | +1908 | +1908 | |||||||||||
| 第四水準漢字 (第二面への追加) |
- | - | - | +2436 | |||||||||||
| 総合計 | 6802 | 6877 | 6879 | 6067 | 8787 | +4344 11223 |
|||||||||
JIS X0208の表に区点番号を割り振った形のままコードとして使用しても良かったのですが、既に存在する情報交換用符号「ASCII」やそれを真似した「JIS X0201(旧C6220)」用に作られたコンピューターでは色々と問題が発生するので、この方法は現実的には使えません。
そこで日本のインターネットの草分けである団体JUNETではJIS X0208を94×94の正方形状の配置のまま、コンピューターで使えるように移動させたコードを運用し始めました。具体的にはX0208では表は1区1点(俗に区点コード0101という)から始まりますが、これをISO 2022に準拠するように一バイト目「21」の二バイト目「21」つまり0x2121から始まるようにしました。図的には水平・垂直方向に0x20だけ移動させて使うとしたのです。
この方法ならばISO 2022に準拠し、全世界との互換性が図れます。むしろC6226(現X0208)は、それを意図して表までは作ったが、実装方法は勝手にやってくれという態度をとったと言った方が良いのかもしれません。
| 文字集合 | JIS X0208 (旧C6226) |
日本でよく使いそうな記号や漢字を94×94の表にまとめた。ISO 2022で利用しやすいように94×94にしたが(?)、符号化の方法までは規定しなかった。(1997年改正時に符号化について言及を始めた。) |
| 符号化 文字集合 |
JUNETコード | ISO 2022(7ビット2バイト拡張)のやり方に従ってX0208の94×94の表を実装。ISO 2022-JPとして国際規格になる。(一般にJISコードと呼ばれるがJISではX0208:1997 付属書2でやっと規格書に表記された。) |
| Shift JIS | JUNETコードではX0201(英数カナ)との切り替え作業が面倒なので、X0201で使わない領域にX0208を流し込んで、切り替えをしなくても共存できるようにした。ISO 2022非準拠。 | |
| EUC-JP | ASCII(英数)との切り替え作業が面倒なので、ISO 2022(8ビット)のやり方に従ってASCIIの使わない領域にX0208の94×94の表を移動させた。JUNETコードと比べると、ASCII以外の文字の各バイトとも0x80を足したと考えればほぼ合っている。 |
現在のパソコン上で主流となっているShift JISの起源は、日本初の16ビットパソコンである三菱Multi16まで遡ります。(Multi16のBASICという説とCP/Mという説がありますが確認は取れていません)
Microsoft、アスキー社、日本アイビーエム、三菱電機により1983年に提案された漢字コードはShift
JIS(SJIS・S-JIS)、MS漢字コードとも呼ばれ、Multi16以降、MicrosoftのBASICやDOSと共に普及していくことになります。
ところで米国の文字コードから名前を頂戴した「アスキー」(実務を行ったのは当時の子会社アスキーマイクロソフト社かも?)が日本の文字集合の符号化方式を策定するというのは歴史の必然でしょうか?
Shift JISの構造は、漢字の第一バイトにASCIIや半角カタカナと重複しない番号を割り当てて、第一バイトを見ただけで文字種がわかるようになっています。第二バイトについても区切り文字として使われることの多いASCIIの0x20~0x3Fおよび制御コードの0x00~0x1F、0x7F(削除のコードが0x7Fなのは紙テープで情報を記憶していた頃の名残)とは重複しないように配慮がなされています。
日本語を扱うときにはX0201、X0208という全く別の規格を利用することとなりますが、JUNETコード(ISO 2022のサブセット)では、これが同じ番号に重なってしまいますので、X0201、X0208の文字集合が混在する場合には区別のためのKI(KANJI IN)、KO(KANJI OUT)という特殊な符号(ISO 2022を簡略化した制御符号)を付加しなくてはなりませんでした。
しかしX0201、X0208両方の文字集合を面倒無く利用することを目的として開発されたShift JISでは、X0201で使用しない部分にX0208文字集合を当てはめることにより、文字が例外なく1枚の文字面に存在しているかのように配置されています。このため特別なことをしなくとも英数カナ(X0201)と漢字・非漢字(X0208)を併用できるのです。特別なことをしなくともよいということは、つまり非力なシステムにも優しいということで当時のパソコンに不可欠な手法でした。また文の長さと情報のバイト数が比例する点も一般に好まれる点です。
欠点としては以下のような点が挙げられます。
さらにShift JISでは2バイト文字を割り当てようにもの第一バイト目の領域が狭いため割当て可能な2バイト文字の数が制限されてしまう問題がありました。JIS X0212(補助漢字)のサポートなど、文字拡張については絶望的と思われていましたが、JIS側が1997年にShift JISの存在を公式に認め、2000年にはShift JISのためと言わんばかりに第三水準・第四水準漢字を制定する形で文字の増強が図られようとしています。(実用上使えるのかは後の節で…)
Shift JISの他のコードにない大きな特徴は1バイトカナが問題なく使用できる点ですが一方では使用できる文字数を増やすための障害となっています。このためJIS X0208:1997では1バイトカナは将来廃止、そのコード空間を漢字の拡張にあてる旨の方向性が示されています。日本語処理の黎明期において1バイトカナから漢字への円滑な移行を促した役割は非常に大きい一方、Windows時代には1バイトカナの存在価値が無くなり、いよいよ廃止論へ動き出したわけです。その広大な跡地に漢字を拡充するに至るまでShift JISが現役であるかは非常に疑わしいところですが。
なおShift JISは国際化による多言語処理の流れに対し、ISO 2022に準拠しないという覆しようのない事実が存在し、規格自体の将来性に暗い影を落としています。国際標準の地位を得ようとしているUNICODEに対する優位性は、国内の互換性という側面を除けば全くないのが現状であり、将来も変わることはないでしょう。
Shift JISのようにX0201とX0208を特別な処理無しに扱いたいという動きは、大型コンピューターの世界では日本語EUC(Extended UNIX Code)として結実します。さすがにShift JISのISO 2022非準拠、2バイト目がASCIIと誤認されるなどの欠点はイヤじゃという反省からか、X0201英数字は普通にそのままで、漢字はX0208の94×94のブロックをそのまま0xA1以降にシフトさせました。1バイトカナはコードの頭に0x8Eを付けてエンベットしています。(1バイトカナはEUCでは2バイト長になります。) さらに実装環境が対応していれば補助漢字も使用可能で、こちらは0x8Fが頭に付けてエンベットしています。(3バイト長のコードになります。)
ISO 2022風に言えばGL=G0=英数、GR=G1=JIS X0208、G2=JIS X0201カナ、G3=JIS X0212です。G2、G3を使うときはGRを使用し、それぞれ0x8E(SS2)、0x8F(SS3)を付加します。結果、1バイトカナは2バイト、X0212は3バイトになりますが、現実にはG2/G3を使えないアプリケーションが多数のようです。
なんだこれではShift JISの方が使える文字面は多いぞ(笑)と思ったかどうかは知りませんが、Shift JISが標準のUNIXも珍しくはありません。EUC-JPが標準でもShift JISもバッチリなUNIXまであるほどです。
日本語EUCの俗称としてはUJISがあります。またEUC(Extended UNIX Code)には日本語EUC以外にも、GB2312-80を使う中国簡字体EUC、 CNS11643-1992-1を使う中国繁字体EUC、KSC5601-1987を使う韓国語EUCが存在します。
どうでも良いような気もしますが、いちおうEUCの弱点を下に挙げておきます。
良くも悪くも日本のパソコン黎明期の主役、日本電気株式会社。PC-9801から漢字ROMを外したPC-9801Aを米国に輸出してみたり、国内パソコンのシェアを8割近くゲットしてみたり、エプソンプロテクトで互換機潰しに無駄な労力を費やしてみたり、メモリーを売りまくるために機種毎にメモリーモジュールの型を変えてみたり、アクサングラーブ(左上から右下へ延びるアポストロフィーみたいな文字)が画面では表示されずLISPプログラマーを困らせるお茶目さんだったり、パイプ(縦線)は中央で分断され祖国統一を果たせない朝鮮半島を形態模写していたり、NECの名が有名になるにつれて正式屋号「日本電気」のデンキを「電機」と書く馬鹿パソコン専門店店員が続出するに至り事態を嘆いた本社が屋号を「エヌイーシー」に改称しようかと議論してみたり、PC/AT互換機に移行しようかと言うときにNXと言い過ぎたためにシェアが伸びなかったりと話題に事欠きません。苦悩が伝説となる辺りは日本版プチIBM的な様相です。
20世紀も終わろうとしている今でもシェア1位というのは割と侮れません(というより他のメーカーがダメ過ぎるのかも)が、NEC本社からは相変わらずお寒い話しか聞こえてこないところがやはりNECのNECたるゆえんでしょう。
そのNECはPC-9800シリーズ(1982年~)へ、後にNEC拡張文字、98文字などと呼ばれることとなる独自の機種依存文字を搭載。シリーズ・機種依存文字ともに国内標準の地位を獲得するとともに数々の悲劇を生むこととなりました(笑) なんと言ってもシェア70%以上で、使い勝手がよいとくれば知らず知らずのうちにNEC拡張文字を使うユーザーも多かったのですが、普段NECのシェアや体制に不満を持つ他機種ユーザーの不満の捌け口となりました。今で言うイジメです。
| 祝・JIS昇格 | 保留領域化 | 駆逐 |
| ①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ㍉㌔㌢㍍㌘㌧㌃㌶㍑㍗㌍㌦㌣㌫㍊㌻㎜㎝㎞㎎㎏㏄㎡㍻〝〟№㏍℡㊤㊥㊦㊧㊨㈱㈲㈹㍾㍽㍼・・・∮・・・・∟⊿・・・ | ≒≡∫ ∑√⊥∠ ∵∩∪ |
NEC選定 IBM拡張文字 |
Windows3.1が標準的に使えるようになるとPC-9800やエプソンPCシリーズ以外でも使われるようになり、もはやJIS以上の標準となった「NEC特殊文字」ですが、2000年にはついにJIS X0213:2000という形で昇格しました。PC-9800シリーズの功罪は残存PC-9821現行機種(21は21世紀の21ってくらいだし)と共に21世紀へ生き延びる事となり、今までさんざん機種依存文字だと言葉の暴力を振るって正義感タップリだったMacintoshやUNIXユーザーの皆さんが、やはり小学生のガキ並に馬鹿だったということが証明される事態に発展してしまいました(笑)
| ●機種依存文字とは | |
| 機種依存文字とは、ある国際的・国家的・業界的な標準規格の文字集合を使用しているシステムなのにもかかわらず、その標準規格に規定がされていない、または適合しない文字のことです。 例えばJISが定義している漢字文字集合であるX0208は全てが埋まっているのではなく、未定義状態の場所が存在し、この定義されていない場所に各企業が勝手に文字を割り当てたのが「機種依存文字」です。 有名どころでは標準規格よりよっぽど使われていたNEC拡張文字「98文字」やMacOSの「KT7依存文字」などです。(当時はMacOSと言う正式名称は存在せず、英語版をSystem7、日本語版を漢字トーク7略してKT7と呼んでいた。) 各企業ともユーザーの利益のためにと考えて増やしているので、必ずしも悪いとはいいきれませんが、通信などでは混乱の元となっています。幸いにも一番問題となりそうなNEC-Apple間でも文意にそぐわない記号に化けてしまうために、多くの場合は化けていることは分かりますが、イジメの原因になるという問題外の問題が発生するのが難点です。 NECの丸数字などは多くの支持を集め、普及が著しかったために2000年にはJISに取り上げられました。IBM拡張漢字も、一部では梯子高(3~5画目の口がハシゴ状になっている異体字)などを印字するときなどに用いられるなどの利益をもたらしています。 謎なのがKT7依存文字で、「おまえはこれがなきゃ困るのか?」と聞きたくなるような文字の羅列になっています。DTPパソコンぶっているくせに「(日)」などまで文字にしているお馬鹿な例もあり(笑) 「そんなの自慢の機能で組版せいっつうの」とツッコミたくなるほど頭の痛い状況です。しかもUnicodeに採用されているし…。 奴らは一太郎でも大して苦労せずにできることが、できないのでしょうか?(笑) なお最近よくお目にかかる例としては、IBM PC/AT互換機でアクサンテギュー付きのアルファベットや罫線素片など、ISO 8859のいずれとも異なる文字がアサインされているのが誰にでも分かる体験でしょうか。パソコン起動時のBIOS画面表示で使われている(無い機種もあるけど)罫線がソレです。画面表示が日本語モードに切り替わったときにカナ文字に変わるので分かりやすいと思います。(←日本語モードで化けるから機種依存なんじゃありませんよ) ちなみに昔、Shift JISは機種依存文字があるからダメだという発言を見たことがありますが、それは間違った論理です。まずよく考えてみてください。 文字をネットワークに流す行為(目的)は符号化方式(手段)が有ってこそ成されるわけですが、この問題の場合は手段(Shift JISという符号化法)⇔目的(文字)というわけではありません。結論から言えば、どこかの文字集合に文字があったからこそ、符号化されてネットワークを飛び交うのです。 機種依存文字は各メーカーがJIS X0208(NECの場合はC6226-1978)という文字集合に独自の文字を加えた結果と考えることができ、文字集合と符号化の間に1対1の関係が整っているならばShift JISであろうが、JUNETコードであろうが、EUCであろうが機種依存文字は符号化できてしまうのです。特にJUNET、Shift JIS、EUCはX0208を単純に位置変換しただけですので尚更です。(たしかNECのBIOSではJUNETコードを入力して画面に表示していたと記憶しています。) 例えばインターネット経由で「①」という文字をメール送信してみてください。キーボードから入力されている時点ではShift JISならば「0x8740」ですが、インターネットに発信する段階で一旦ISO 2022-JPに変換して「0x2D21」という数値に置き換えます。これがインターネットの中を通って、相手に届きますが、この時の文字はShift JIS符号ではありません。さて相手先で丸数字の1は正しく「①」と表示されていなかったのでしょうか? 機種依存文字の問題は、単にC6226+NEC、X0208+IBM、X0208+MacOSという独自拡張を施された文字集合が存在するという話なのです。 |
|
SJIS:F040~を95区~に相当すると考えます。(JIS X0213:2000では2面○区と新定義されました) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
JISでは技術の発展状況に合わせた規格作りを行うために5年おきに規格を見直していますが、文字コードを語る上で避けては通れない大事件が1983年に改正時に起こりました。
1983年(昭和58年)頃は、国民が使ってもよいとする漢字を約1850字に制限していた当用漢字の時代が終わりをむかえ常用漢字表が制定された年です。
また日本国民が漢字を使わなくなれば日本に真の民主化が訪れ世界は平和になるという妄想「漢字制限論」も横行していました。漢字制限論者にとっては、1983年に見直しが行われるC6226は格好の的と見えたのか、JISを改悪することが悲願を成し遂げるための布石と考え、「常用漢字との整合性をとるため」「後に制定される24ドット印刷用の字形で混乱を生じさせないため」などと某オウム並の理論展開で規格改正をし、混乱を巻き起こしましたというのが定説です(笑)
実際には「常用漢字との整合性」という主張には矛盾も多いとの見解が今でも声高に言われます。また「24ドット印刷用フォントの規格制定に際しての混乱を避ける」との理由は明らかにおかしな主張です。24ドットという非常に狭い領域の中で無理矢理に表現するための「ドット絵」と、普通の「活字」の間に字体の完全な互換性が必要なのでしょうか?(第一、ドット絵を見て同じと断言できないようなドット絵もあるし…)
改正の内容を見てみると、漢字4字、特殊文字39字、罫線素片32字の追加はよいとして、22組の旧字体/新字体の入れ替え、244文字(見方によって数字は前後する)の字形の変更が加えられています。字形の変化もなかなかデンジャラスですが、本格的に深刻なのは新旧字体が入れ替わってしまったことでしょう。新旧字体の入れ替えに関しては今も賛否両論が熱く議論されるほどです。
もっとも当時、一般的に普及しだした日本語ワードプロセッサー=ワープロでは文字を構成するドット数は24程度だし、JIS第二水準漢字用のROMを別途購入しなければ表示すらできない(うちのワープロはフロッピーディスクに第二水準漢字が格納されていた)時代だったのでパンピー(一般人)の目は何とか誤魔化せたのかもしれませんが、当時の主流であったNEC PC-9800シリーズには規格改正後も約13年間に渡って(従来との互換性が大幅に殺がれるためか)古い工業規格が適用され続けるほどの混乱でした。
ISOでも1978年版と1983年版(1990、97年改正は1983年版の改正として扱っている)は別物として登録しています。
なお現在ではJIS X0208-1983として知られていますが、これは198?年にJISに情報分野のXが新設され、そちらへ移動したための改称であり、C6226-1983とX0208-1983は同じ物を指します。古いワープロ辞典などにはJIS C6226-1983と表記が見られます。(なおJIS X0208-1978などという表記を見ることがありますが、厳密に言えばこんな物が存在するはずもありません。これは話を簡単にするために今でも万有引力が理科の教科書に載っているのと同じ類のウソだということは頭の片隅にでも置いておくとよいでしょう。π=3も許される時代だしぃ)
1990年の改正では二字の追加が行われましたが、俗称も付かない程度のジャブでした。実用上はほぼ変化無しと言いたいところですが字形変更が145文字ほどあるようです。印刷を業者に任せたいい加減な83JIS以降の例示字体に関する混乱を収拾するために規格票を平成明朝体で印刷したそうです。(それで具体的に何が解決するのかは不明(笑))
1990年10月に従来の第一水準・第二水準漢字では足りない漢字等を追加するために制定された6067字からなる文字集合で、JIS X0208-1990と合わせれば12946(漢字12156、非漢字790)の標準文字が使えることになるかに思えました。
が、補助漢字の扱いを受け、ついには日の目を見ない規格として歴史の陰に埋もれようとしています。規格制定直前まで第三水準漢字と称されていたのが一転、システムへ組み込むとシステム単価が高くなる、全員が必要としているわけではないなどの意見が前文に書かれるなど結局は「補助」の扱いを受けるようになりました。実際に搭載した事例にWindows98やMacOS8も含まれますが、これはUnicode対応の一環。JIS補助漢字はUnicodeとTRONに丸呑みされるために生まれたようなもので、一部のEUCなどを除けば「X0212」として組み込まれることなく消滅しようとしている規格です。
ちなみにX0208-1997(字は1990と同じ)と補助漢字を合わせても戸籍法上の人名をすべて表示し、印刷するには69文字の異体字、52文字の人名漢字が足りません。(2000年現在)
批判として、実際の用例ではなくメーカーの漢字表を基準にしたこと、辞書になく音義未詳の字が含まれていること、1983年のJIS改定のために消滅した文字を28字復活させているが何を根拠に26字を選定したのか不明であること、Shift JISでは全く使えない等が挙げられます。JISに無いとはいえ(1997年まではX0208に符号化法が一切触れられてもいなかった)Shift JISに対応しないのは規格としては致命的でした。
名称が「7ビット及び8ビットの2バイト情報交換用符号化漢字集合」に変更され、下の問題についての具体的な解決が図られています。
①⑥符号化について初めて規格内で触れています。俗に「JISコード」と呼ばれてきたコードは実はJUNETというネットワークに関する研究集団が独自に作ったコードで、正確性を期すならば「JUNETコード」または「ISO 2022-JP」と呼ばなければなりません。いわゆる「JISコード」とはJIS X0208の文字集合を用いながらもJISとは何の関係もない符号化文字集合のまま国際標準にまで上り詰めていたコードなのです。
| Shift JIS MS漢字コード |
JIS X0208:1997 附属書1 「シフト符号化表現」 文字集合にJIS X0208を用い、符号化方式にはJISに基づかない独自の方式を使った符号化文字集合。ただし後に制定されるJIS X0213:2000との混乱を招く恐れが高いことから、この附属書は「参考」扱い。 |
| JUNETコード ISO 2022-JP |
JIS X0208:1997 附属書2 文字集合にJIS X0208を用い、ISO 2022(JIS X0202)7ビット拡張法のサブセットとして機能する形で符号化した符号化文字集合。やっとJISコードと言っても良くなった?! |
| EUC-JP (日本語EUC) |
JISでは特に触れられず。 文字集合にJIS X0208を用い、ISO 2022(JIS X0202)8ビット拡張法のサブセットとして機能する形で符号化した符号化文字集合。US-ASCII、JIS X0208、JIS X0201カナ、JIS X0212補助漢字が(実装されていれば)使用できます。 SUNのSystemVなどUNIXで広く使われていますが、どこかが規格化している訳でないので広い意味でのローカルコードです。(AT&Tが定義しているとの文献がありましたが確認に至っていません) なお1バイトカナの実装は最近までほとんどされていませんでした。 |
②従来では扱いが曖昧だった空き領域の使用が明確に禁じられました。97JIS改正時には
がハッキリしました。空き領域の使用に関しては過去の規格策定者のポリシーの欠如を指摘していると見て良いでしょう。本来、文字規格の空きは将来拡張用が主目的であり、ユーザーに開放するならば異にする領域を割り当てるべき、もしくは拡張を最初から行わない。これは素人目でも当たり前のことでしょう。
なおISO云々は上の主張に箔を付ける目的と思われます。国内規格と国際規格は厳密には違う物であり混同されるわけではありません。
④⑤今までの改正時に見直されてこなかった様々な問題に対する決着を付けようということでしょうか。採録元が不明で読むことすらできない「幽霊字」も12字存在することが明らかになりました。
⑦丸付き数字、単位記号、ローマ字の長音記号付きラテン母音字などは合成文字として生成できると漠然と信じられ、JIS
X0208-1983に至っては合成用の丸「◯」(2区94点LARGE CIRCLE)まで作ってしまう混乱ぶり。しかし現実的には生成不可能だったり、生成しても実用に耐えるかは怪しいといえる状況でした。さらに不可能を可能にせんがため丸数字などのメーカー独自実装が横行し、情報交換の際の混乱を招いたりもしました。この期に及んでやっとJISで合成行為が不可能と明言すること線引きをしました。
日本語は文字合成の必要のない文字体系であるし(欧州や朝鮮は文字合成技術はほぼ必須)、日本人の字形へのこだわりは尋常ではありませんので、ここらで一発否定してしまうのは妥当でしょう。
JIS X0213:2000 8より引用
1面2区94点のLARGE CIRCLE(大きな丸)“◯”は、現在位置の前進を伴う文字であり、文字合成を実装する場合に、現在位置の前進を伴わない文字として用いてはならない。
今までJISで規定していた文字集合X0208には日常的に使用する記号や漢字などが不足しているとして各界からの不満の声は絶えませんでしたが、規格制定から22年目経ってやっとというか遅きに失したというか、とりあえずJIS X0208の拡張版が登場しました。遅きに失したとはいえ、X0208:1997改正作業で現実を見据えたメンバーが制定に当たったという意味においては2000年でかえって良かったのかもしれません。
現行のシステムで文字の増強を行う場合には、他の文字面を新たに生成するよりは、現在使用しているX0208の空いている領域に新たな文字を埋めていく方がシステムの変更点が小さくて済み、システムの大幅な設計変更をしなくとも済むことが容易に想像できます。
そこでX0213ではX0208の空いている部分に文字を追加することを前提とした拡張方式を採っています。X0208の6879字に4344字を追加して、合計11223字になります。
1990年のJIS補助漢字(JIS X0212)では文字面を変更する仕様が徒となったのか、多くのシステムで利用されずに終わりましたが、X0213では文字面を切り替えることを想定していないShift JISでもそのまま利用できるように、X0208と同じ文字面~Shift JIS外字領域(2000JISでは第二面の一部に相当)に収納可能な構成となっています。
工業規格としてはJIS X0208:1997で使用禁止と叫んだばかりの空き領域(保留領域)へ舌の根も乾かぬうちに文字を拡張してしまったことは大きな問題だと思いますが、主に使われる「98文字」部分は規格へ組み込む事からも混乱は許容範囲内に収まったといえるでしょう。(流石に「98文字化けまくり」なんて事態になっていたら、誰も使わんでしょう。)
もしもX0213が1990年代前半…まだDOSが闊歩し、Unicodeが何も具体的な形を持っていなかった時代に施行されたならば、来るべきWindows3.1時代が拍手で迎え入れたことでしょう。しかし現在日本で使われているパソコンの多くで稼働しているWindows98/NT4/2000はもちろんMacOSなどの最近のOSの内部ではUnicodeに一度置き換えられるために、Unicodeに2000JISの新規漢字を登録した上で、Unicode⇔JIS変換テーブルの更新をしなければ対応できないのが現状です。(たとえX0213対応を謳うMacOS 10でも同様です。)
例えばIE5.5の文字処理にはUnicodeを使用しており、これはWindows98以降では順当な設計ですが、このような場合はX0213漢字をシステムの変更無しに利用することは不可能です。試しにJISの1区~94区+外字領域の表を用意しましたので表示してみてください。Unicode⇔Shift JISテーブルに存在しない2000JIS文字は当然まともに表示されません。 (フォントはVectorなどでKandata、Habianを検索してインストールしてください)
そして比較のためにNetscape 4.xあたりをインストールして見てください。設計が古いためにJISコードなどをそのまま処理してしまうNetscape4.xなどでは逆に使用できるという皮肉な面も御覧いただければ幸いです。
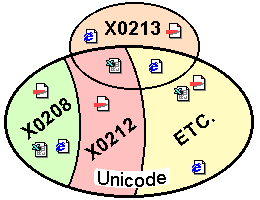 データの利用・変換・互換性の面では、X0208、X0212、X0213、Unicodeと下手をすれば3つ4つの規格の間で頭を抱えるハメになる危険性もあります。特に似て異なる規格の文書ファイルが乱立することになれば自動的に判別することは不可能となり、必ず誤判断も起こります。特に素人ならば訳が分からず途方に暮れるのみです。
データの利用・変換・互換性の面では、X0208、X0212、X0213、Unicodeと下手をすれば3つ4つの規格の間で頭を抱えるハメになる危険性もあります。特に似て異なる規格の文書ファイルが乱立することになれば自動的に判別することは不可能となり、必ず誤判断も起こります。特に素人ならば訳が分からず途方に暮れるのみです。
また既に未定義領域への拡張を施してしまった物については、X0213との区別を付けることは非常に難しく、これで商売をしている業界では受け入れがたいでしょう。しかもUnicode化が進行している今、意味もなく全く別物を用意されたのならば困惑するばかりです。
もともとJIS2000文字の多くが既にUnicodeに収録されています。また新規に登場した文字ですら近い将来にはUnicodeに収録されるでしょう。いわば千にも満たない文字をUnicodeへ献上するためだけに存在する物を、いたずらに制定したのでしょうか。そして何故わざわざ外字とJISを衝突させたのでしょうか。
ではまず2000JISの利益は何でしょうか。それは今まで何処の規格にも書かれていなかった文字が何処かに登録されること、そして人名漢字や欧州文字などの増強も見逃せない要素です。それ以上にパソコンユーザーにとってはShift JISなどでは使えなかった漢字が利用できる可能性が提供されたことです。(OSが対応すればの話なので、あくまでも可能性ですが…)
また人によってはJISの策定に当たり、情報開示がなされ、一般の意見が聞き入れられる土壌が確保された事実に利益を見いだすかもしれません。規格策定中の参考資料が今でもネット上に多く散在し、世界中のどこからでも自由に無料(電話代はなんて野暮なことを言ってはいけません(笑))で閲覧することができるという事実は、WWW登場以前には考えられなかった事態です。
WindowsはUnicodeに向かっている、WindowsでShift JISを使うのは時代遅れだと反論する人もいるかもしれません。確かにMicrosoftのWindowsやOffice、そしてJUSTSYSTEMの我らが一太郎&ATOKなどは、Unicodeコンソーシアムの正会員だけあって対応は万全なのかもしれません。
しかし中小ソフトハウスや旧来のソフトウエアはどうでしょうか? 少なくとも2000年現在ではUnicodeをサポートしていないソフトの方が多いのです。このようなソフトウエアが多い中では新たな文字面を作るようなことをするより、フォントがすり替わるだけで既存のシステムでも対応可能となる2000JISのアプローチは極めて現実的です。
また将来はUnicodeに全てのシステム・データが移行する日が来るでしょうが、その時に、ここからここまでは日本で使う文字だから日本のパソコンは標準搭載しておけいった線引きに利用できます。
例えば線引きがあれば、このパソコンでは表示できて、あのパソコンでは表示できないといった心配が無くなるとまでは行かなくとも軽減はされます。そしてフォントを販売するフォントメーカーはX0208,0212,0213の文字が入っていると謳えばユーザーが安心して買ってくれるわけです。更にフォントメーカーはUnicodeに登録されているからといって日本ではまず使用しないであろう文字まで作らなければ安心できないといった万国文字集合ならではの問題から解放されます。
一方不利益は何でしょう。大半は、今までの外字が文字化けして混乱するという一点に集約されるのではないでしょうか。しかし混乱が起こる原因と責任は何処にあるのでしょう。それは外字を利用したユーザーが原因であり、責任は本人がとるべきです。
なぜならば外字(NEC特殊文字などを除く)を使っているからには、他のシステムと互換性が望めないことは解っていたはずです。そう最初から他環境では文字化けすることを解りきって使っているのです。解っていないのならば認識不足か(厳しいようですが)無能と言わざるを得ません。
不利益を被ると言っている人はどうすればよいかと言えば、実は今までのシステムを現状のまま使い続ければよいだけの話です。よく考えれば簡単な話です。べつにアナログ放送方式からデジタル放送方式のテレビに買い換えろとか言っているわけではありません。もっともスピード違反で捕まった運転手ですら文句を言うのですから、このような問題はなかなか円満解決とはいかないでしょう(笑)
1997年頃のUnicode事情はと言えば、未だ普及段階に至っておらず、将来の何時の時点で普及するかも不明でした。しかし現在は少し事情が変わり、WindowsNT5ことWindows2000以降は急速にUnicodeに移りつつあります。Windows95の系図も途絶え、ウィスラなどというコードネームも聞こえてきます。今までいい加減に作られてきたビジネスソフトは、NT(Windows2000)への移行ではバージョンアップしなければならず、世代交代は意外と早く進むかもしれません。
| JIS X0213:2000の規定と参考 | ||
| 規格票 | 4344文字の文字集合と ISO 2022系の符号化方法 |
規定 |
| 附属書1 | SHift JIS系の符号化方法 | 参考扱い |
| 附属書2 | EUC-JP系の符号化方法 | 参考扱い |
| 附属書3 | ISO 2022-JP系の符号化方法 | 参考扱い |
例えばWindowsでは基幹部はUnicodeで動いていますが、過去との互換性のために残されている古いシステムコールはUnicodeをShift JISに変換してからアプリケーションプログラムに受け渡す仕組みで動くようになっています。そうなると要はUnicodeで動作するWindowsがUnicode⇔2000JIS変換を行ってくれるかが焦点となりますが、これが難題です。
まず2000JISは一部とはいえUnicodeに登録されていない文字があります。少なくともUnicodeコンソーシアム正会員であるMicrosoftが今更Shift JISを基準としたシステムに戻るはずがありませんから、第一にはこれをUnicodeへ登録しなくてはなりません。実際にはISO 10646-1へ登録後、Unicodeが自動的に登録する流れになるでしょう。
そしてそれが終わったら今度はWindowsのUnicode⇔Shift JIS変換表を改正しなくてはなりません。とはいえMicrosoftが無償バージョンアップしてくれる日が来る前に、人類は滅亡してしまうでしょうから(笑) 結局新しいWindowsが登場するのを待たなくてはならないでしょう。
そうすると晴れて2000JISがWindowsの一部となるのは早くともWindows 2002あたり、運が悪ければ更に数年待たなくてはなりません。
さらにMicrosoftは実装しない可能性もあります。なぜならShift JISはMicrosoftから見れば過去の規格です。ユーザーが幾ら使っていようが、いまいが、今はUnicodeに移行したいのです。そのような会社がわざわざ危険を冒してまでX0213を実装するでしょうか? 気まぐれなMicrosoftの判断がどう転ぶかはなんてことは分かりませんが(笑)少なくとも現実問題としては採用するに賭けて得をすることはないでしょう。
なお従来のシステムをServicePackなどで改良することは論外と考える方がよいでしょう。なぜならWindowsの表示を司るGDIの変更にOSやアプリケーションソフトが耐えられるかは大いに疑問ですし(私見)、GDI自身の整合性すら取れなくなるかも知れません(私見)。それ以外の処理でもOSやアプリケーションソフトが持つ高速検索ルーチンや文字列処理ルーチンが正常に動作するかは不明で、正常に動かないソフトが出てくると断言しても良いくらいです。(プログラムの一般論) いやここは一発、断言しなきゃいけないところかな…。
残念ながら、ソフトの対応が間違えなく分かれる以上はユーザーの混乱を避ける意味でも、Microsoftは絶対に対応してはいけないと言わざるを得ません。
| 現行規格番号 | 標題 | 制定年月日 | 最終改正日 | ISO規格番号 |
| JIS X 0201:1997 (旧C6220) |
情報交換用符号(1969、1976) 7ビット及び8ビットの情報交換用符号化文字集合(1997) |
1969-06-01 | 1997-01-20 | ---- |
| JIS X 0202:1998 (旧C6228) |
情報交換用符号の拡張法(旧) 文字符号の構造及び拡張法(1998) |
1975-03-01 | 1998-01-20 | ISO 2022 |
| JIS X 0208:1997 (旧C6226) |
情報交換用漢字符号系(1978、1983、1990) 7ビット及び8ビットの2バイト情報交換用符号化漢字集合(1997) |
1978-01-01 | 1997-01-20 | (ISO 2022-JP) |
| JIS X 0211:1994 (旧C6323) |
表示装置に対する情報交換用制御文字符号(旧) 符号化文字集合用制御機能(1994) |
1986-11-01 | 1994-10-01 | ISO/IEC 6429 |
| JIS X 0212:1990 | 情報交換用漢字符号 ― 補助漢字 | 1990-10-01 | ---- | ---- |
| JIS X 0213:2000 | 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合 | 2000-01-20 | ---- | ---- |
| JIS X 0221:1995 | 国際符号化文字集合(UCS) ― 第1部 体系及び基本多言語面 第2部があるのかは謎(笑) |
1995-01-01 | ---- | ISO/IEC 10164-1 |
国際標準化機構(ISO)は、ISO 2022とは異なるアプローチから全世界の主要な文字を含んだ単一の文字集合を策定するためにISO 10646の策定作業に着手しました。従来用いられた2バイトでは当初より全世界の文字を収容することは不可能な事を理解していたのか4オクテット(32ビット)単一長コード(群面が変わらなければ16ビット長に省略可)としての策定作業が始まりました。
この便利な規格案は規格原案第一版(DIS 10646 1.0)として1991年に投票にかけられましたがUnicode陣営の執拗な働きかけにより否決され、さらにUnicode陣営に丸ごと乗っ取られて骨抜きにされてしまいました。10646-1の-1が物悲しさに拍車をかけています(?)
全世界の文字を収録するときに似たような文字を統合すれば2オクテット(16ビット)で表しきれるだろうという、さすがは94文字で事済むお国柄の米国企業を中心に提唱。最初から破綻した思想が元となっていますが、米国中華思想(宇宙は米国を中心に回っているという思想)が生んだ発想のためにタチが悪く、さらには、恐らく表意文字を1文字も登録していないのでは無かろうかと思えるカナダ代表が漢字についてチャチャを入れるといった端から聞くだけでは冗談とも思えるような経緯などを経て現在に至っています。良し悪しは別にしても「実際に運用することのない連中はこれほど無責任になれるのか」と嘲笑されるのも当然です(笑)
最初から行き当たりばったりだった規格は当然のごとく破綻を招いているのは明らかですが、とりあえず英語圏以外の文字も含めて統一的に扱う仕組みさえできれば、うちのソフトが売り込めると目論む英語圏のソフトウエアベンダー等を中心に大人気です。
1991年時点ですら、中・日・韓の3カ国語だけで規格化されている文字だけで2万文字程度(統合方法により数字は変わる)、ハングルは別に1万文字を越えます。また当時の現規格では不足している文字が存在した上に、他にも台湾・香港を含め搭載しなくてはならない文字は山ほど存在します。
将来を考えれば規格策定時には早くも2オクテット固定長という計画が近く破綻を迎えるであろうことが分かります。(16ビットではどんなに効率が良くしようとも65536符号しか作れない)
結局、今のところはよくある一部2階増築済み(サロゲートペア)程度の馬鹿さ加減で済んではいますが、文字に関する研究が進めば字体の登録が更に激増し何時の日にか超サロゲートペアとかいう裏技も生まれかねません(笑)
人類は西暦2000年問題(Y2K)で自身の思考の限界の一端を見ました。問題のプログラムを作った誰もが2000年問題は極論と昔は考えていたか、考えも及ばなかったはずです。(ちなみに私は"極論"という単語はその人の思考の限界を示すものだと昔、指摘され、目から鱗でした。) さて100万文字なんて埋められるはずもないなんて考えているのは技術屋の浅はかな考え方だったと嘲笑される日は何時のことでしょうか。
ところで一般にUnicodeは米国人の横暴、文化侵略・破壊・軽視などと文句を言われますがそれも見当違いです。CJK(中国・日本・韓国の表意文字)パートに関しては中・日・韓の当事者間でも実務レベルの調整が行われているために、「アメ公が作った無意味な羅列」という批判は実際には的はずれです。しかしそれでも、最初の理想論だけが素晴らしく聞こえる現実を無視した規格であることが間違いないのは何とも…。
さてUnicodeバッシングはここまでにしておいて、Unicodeが本来目指していたハズのところはどこでしょうか? それは文字を収集する事ではなく、スクリプトを収集する事です。
文字を扱う者にとって「くち高」と「ハシゴ高」は同じ文字か違う文字かという問題は有名どころでしょう。この問題に対しIBMは(商業上の問題からか)違う文字としました。しかし2000JISでは同じ文字としました。歴史を戦前まで遡れば、「ハシゴ高」は手書き独特の字形であり、そんな時にでも印刷の字形は「くち高」でした。その点をJISでは考慮したものではないかと思います。(字数の制限がより緩ければ「ハシゴ高」も2000JISに入ったかもしれませんが。)
JIS漢字集合(プリンター用24ドット字形などは含めません)では過去も現在も具体的な字形は一切規定していません。人間の世界でも無意識のうちに微妙な文字のハネ、トメ等の違いを無視して同じ字と認識しています。例えば木の縦の棒の先がハネていたかハネていないかったかの差異で違う文字とする人は皆無でしょう。たまに×にする教師はいるかもしれませんが(笑)
本来、文字とは抽象的な概念であり、字形が厳密に定まった物ではありません。多少の個性が出ても仕方のない物ですし、気にする必要もありません。だからJIS規格票でも「例示字体」という言葉を使い、これはあくまでも一例ですよという態度を示しているのです。
さてスクリプトの話に戻ると、日本では多くの人が4つのスクリプトを使っています。それは、平仮名、カタカナ、英数字、漢字です。(英語とアラビア数字も独立したスクリプトだと考えることもできますが、ここではとりあえず一つとしておきます) 一方、中国人と、朝鮮人、日本人は漢字という1つのスクリプトを共有しています。
この考え方に基づいて文字を整理したのがCJK統合漢字です。中・日・韓の三国では同じルーツを持つ漢字を使用していますが、これらは元を正せば同じ原点に達するのは明らか。字体の意味やルーツ、字形、歴史を考慮しながら整理統合を行うことはできるはずです。これには誰も異存はないでしょう。
しかしCJK統合漢字では、一般感情を軽視しすぎた(軽視せざるを得なかった)感があり、あまりにも一般の感覚ではかけ離れた文字までを同定(同じ物だと認定すること)した例も多く、学術的には問題が無くとも、一般の理解からは乖離している面もありました。そしてついには文化破壊だという批判を痛烈に受けることとなります。
たとえば日本語の文章の中に、密かに中国から取り寄せた類似フォントの漢字を忍ばせたらどうでしょう。おそらく日本人が見れば、日本と中国の漢字の微妙な違いを見抜いてしまうことでしょう。漢字は進化の過程で各国の字形が微妙に異なるという結果を生みました。だから中国と日本と韓国の漢字フォントは異なるのです。
しかしそれで意味が通じなくなることがあるのでしょうか? Unicodeで同じとされている文字を使っていれば外国で印刷した文書も「なんだ、こりゃ」程度で済んでしまうのではないでしょうか。これこそがUnicodeが目指す世界です。
例えば台湾で製造した製品を日本に輸出しようとするときに、台湾版Windowsで日本文を作成・印刷したならば漢字が旧字体だったりしてバレバレかもしれないが、この文書を日本語Windows(もしくは日本で使うためのフォントを入れたWindows)で印刷したならば違和感は全く無くなる、その程度で良いとしているのがUnicodeなのです。
もちろんいくらUnicodeだからといって、今までにあった各国の国内規格の異体字をないがしろにする訳ではありません。各規格内で異体字として登録されている文字については原則、全て収録する方針であるため、JIS→Unicode→JISと変換したからといって、元は異なるのにいつの間にか同じ文字コードに変化していたなんてことがないようにしています。JIS X0208だけをとってみても亜(新字体)と亞(旧字体)が登録されているなど、本来、同定すべきかもしれない文字が実用上の観点から別の文字として登録されている現状を考慮したものです。その点はご安心下さい。(X0213はどうなるか知らないけど…)
ところでこの種の話題について語っている論文などは見たことがありませんが、私が心配するのは文字の進化です。既にアルファベットなどは字形の進化は終えている(変える必要がない)と言って良い状態ですが、漢字に関しては現在進行形で文字が変化しています。例えば20世紀中に限っても中国では漢字の簡略化が進み「簡体字」なるものが登場し、台湾や日本とはかなり趣が変わってきたりしています。
各国の文字をスクリプトで一括りにしてしまうUnicodeでは、何十年後の文字の変化に対応できるのか否か。日本でも旧字体と新字体の違いだけで別々のコードへ登録されている文字が数多くあります。もし2国間で全く違うベクトルへ向かって進化してしまった文字が出てきたら、どちらに合わせるのか、それとも新しい文字コードを作ってしまうのか。
そういった問題に対してUnicodeコンソーシアムはどのように考えているのでしょうね。
最後に忘れてはいけないのがTRONでしょうか。1980年代に日本の教育用コンピューター標準のOSとなろうとした時には、米国の圧倒的内政干渉圧力で潰された実績もあり(笑) 2000年現在はMSならぬNS…ナショナルセミコンダクター社(not 松下)もちょっと気にする、純国産OSです。
某純国産ロケットH2Aとは違い、現在既に国内企業の多くが影ながら使用しているというところが実用的です。あなたの家のテレビやエアコンが一般保護違反でフリーズ(動かなくなること)することがないのはTRONの御陰かもしれません。
TRONコードでは48400字入る面を31面持ち(さらに拡張も可能)、面切り替えにより、合計約150万字の文字を収容できます。2000年現在ではBTRON仕様に基づくOS「超漢字」が発売され、これには128450文字が収録されています。2000年7月に発売の「超漢字2」ではJIS第3水準・第4水準の4344文字などが加わり134567文字に拡大しています。
TRONコードは複数の文字集合を収容するという方針を取っていて、重複した文字を許していますが、これは各文字集合の収集方針や包摂に対する規準などが独自であるため、ある二つの文字を同定すべきか否かの判断が事実上不可能であるという考えです。これは例えば中国語・韓国語・日本語で書くときの判断の「判」は国ごとに微妙に異なりますが別々の文字コードが割り当てられているために、これの判断も可能です。既存の物で例えるならばUnicodeよりISO 2022に近いと言えば分かりやすいかもしれません。
TRONの文字に関する特徴は、文字を集めまくることです。嘘字や俗字についても積極的にコードを割り当てる方針をとっていて、例えば「○○は△△の嘘字である」といった記述すら簡単にできます。
このTRONは純国産OSであるにも関わらず、日本人でも使ったことがある人は僅か、認知度も皆無に近い状況です。もっともパソコンマニアを自称するならばLinuxももちろんですが、TRONの名前くらいは最低限知っておかねばならないでしょう。
| ANSI | American National Standard Organization (米国規格協会) | |
| ASCII | American Standard Code for Information Interchange (情報交換用米国標準コード) | |
| IEC | International Electrotechnical Commission (国際電気標準会議) | |
| ISO | International Standards Organization (国際標準化機構) | |
| BMP | Basic Multilingual Plane (基本多言語面) 用例…ISO10646-1 BMP | |
| DIS | Draft International Standard (国際標準企画案) ※DIS→FDIS→正式規格の流れ | |
| FDIS | Final Draft International Standard (最終国際標準企画案) | |
| IRV | International Reference Version (国際基準版) 用例…ISO 646 IRV | |
| JIS | 日本工業規格 (Japanese Industrial Standard) | |
| EUC | Extended UNIX Code | |
| UCS | Universal Multiple-Octet Coded Character Set ※ISO/IEC 10646 Universal Coded character Set (国際符号化文字集合または普遍文字コード) |
*…濁点ボイスなどは含まれないと思う…(爆笑) アイヌ語表記用の仮名は不明、っていうかアイヌ語の名前自体が認められているかも不明●元から戸籍にある文字の場合
| 制定年 | 規格国:扱い | 規格番号 | 文字数 |
| 1978 | 日本(基本) | JIS C6226-1978 | ('97) 6879 |
| 1980 | 中国簡体字 | GB2312-80 | 7445 内漢字は6763 |
| 1987? | 韓国(基本) | KSC5601-1987? | 8224 内ハングル2350 内漢字4888 |
| 1987 | 中:補助 | GB7589 | 7237 |
| 1987 | 中:補助 | GB7590 | 7039 |
| 1987 | 中国伝統字 | CNS 11643 | 13735 |
| 1990 | 日・補助漢字 | JIS X0212-1990 | ('90)6067 内漢字5801 |
| 19?? | 韓:補助? | KSC5657 | ハングル1930 漢字2856 |
| 19?? | 台:業界標準 | Big5 | 漢字は13051+2 |
| 2000 | 日:基本拡張 | JIS X0213:2000 | ('00) 4344 |