 �u���p�Ł�������́v�ƌ���ꂽ�炱�̕������Ǝv���ĊԈႢ�Ȃ��ł��傤�BASCII������1�o�C�g�����ƌĂ�邱�Ƃ�����܂��B
�u���p�Ł�������́v�ƌ���ꂽ�炱�̕������Ǝv���ĊԈႢ�Ȃ��ł��傤�BASCII������1�o�C�g�����ƌĂ�邱�Ƃ�����܂��B| Copyright(c)AOTAKA 1995-2003 - www.aotaka.jp |
�����̋@�B�̋@��ˑ�������������Ɣc�����A�����Ďg��Ȃ��悤�ɂ��邱�Ƃ̓l�b�g���[�J�[�̏펯�ł���B
���{�H�ƋK�i�iJIS�j�ł͏������p��������߂��Ă��܂��B���j�I�ɓd�q�@��ł͂��̋K�i���V�X�e���̎���ɍ��킹�ăJ�X�^�}�C�Y���ė��p���Ă��邱�Ƃ��قƂ�ǂł��B����Ċ�{�ƂȂ�JIS�ɑ����������͑����̋@�B�ŗ��p�ł���ƌ����܂��B
�u���p�Ł�������́v�ƌ���ꂽ�炱�̕������Ǝv���ĊԈႢ�Ȃ��ł��傤�BASCII������1�o�C�g�����ƌĂ�邱�Ƃ�����܂��B
JIS X0201(Latin) �̓��[����Web�y�[�W�̃A�h���X����͂���Ƃ��ȂǂɎg�p���镶���ł��B���X�͕č��������p��������ASCII�������K�i�Ƃ��Ē�`���Ȃ��������̂ł��B
�Ȃ��S���E���ʂɎg�����Ƃ��ł��镶���ł��̂ŊO���Ƃ̃��[�������ł́A���̕\�̕������g����Ɗo���Ă����܂��傤�B
���~�L���u���v�́AUS-ASCII�ł̓o�b�N�X���b�V���u�_�v�ł��B
���č��ȊO�ł͂��̑��ɂ������̕����ɈႤ���������蓖�Ă��Ă��܂��B
��2�o�C�g�����i�S�p�����j�̉p�����ƊԈ��Ȃ��悤�ɒ��ӁB
���{�H�ƋK�i�iJIS�j�Œ�߂Ă���������p�̕����͈ȉ��̒ʂ�ł��B�����ł̓X�y�[�X�̓s���Ŕ������݂̂��f�ڂ��Ă��܂��B
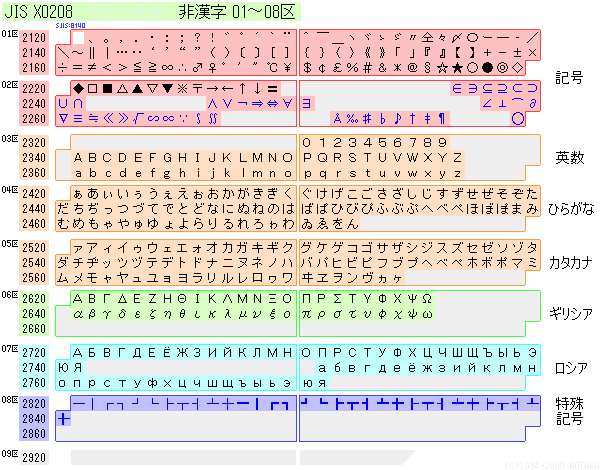
�����͗ʂ������̂ŏȗ�
�����ł̒��ړ_�͐Ŏ����������ł��B�Ŏ�����������1983�N�ɒlj����ꂽ�����ł��B���̂��߁A���ɌÂ����[�v����p�@��p�\�R���i����80%�̃V�F�A�������Ă���PC-9801�V���[�Y�ł��o�܂���ł����B�j�ł͗��p�ł��Ȃ����Ƃ�����AWindows�����y����ȑO�́u��v�Ȃǂ��u�VJIS�����v�ȂǂƋ�ʂ���A�@��ˑ������ɕ��ނ��ꂽ���オ����܂��B
���������ݕ��y���Ă���Windows��MacOS�iMacintosh�j�ł͕W���I�ɗ��p�ł��܂����A���[���@�\�t���̌g�ѓd�b���o�ꂵ���̂͋K�i����̗y����ł��̂ŁA�ʏ�͗��p�ł���ƍl���ėǂ��ł��傤�B
���ɔėp�I�Ɏg�p�ł��Ȃ�������Ꭶ���܂��BMicrosoft����߂��g���ł��邽�ߒ��ԓ��Ȃǂœ����@��������Ă���͈͂Ȃ�Ζ��͂���܂��A���̊����ł͂قڈُ�𗈂������ł��B�ʏ�͐�Ɏg��Ȃ��悤�ɂ��܂��BWindows�A�g�ѓd�b�Ȃǂō̗p����Ă��܂��B
��Windows�APDA�A�g�ѓd�b���[�U�[�͗v����
�@ �ەt��������[�}�����͂�������g���Ă��܂��̂ŁA���ɋC��t���܂��傤�B
���Ɏ��������́uNEC PC-9800�V���[�Y�v�Ƃ����@��ŗ��p�ł��������ł��B1985�N�`1997�N���̓��{�ł́A�ǂ���������PC-9800�V���[�Y���W���p�\�R���̒n�ʂ��߂Ă������߁A���ݍL���g���Ă���Windows���{��łł����ʂɗ��p�ł��Ă��܂��܂��B
���������{�H�ƋK�i�iJIS�j�ŔF�߂��Ă��Ȃ������̂��߁AWindows�ȊO�̃p�\�R����@�B�ŗ��p�ł��邩�́A���̋@�B����ł��B
�Ⴆ��MacOS�iMacintosh�j�ł͓Ǝ��̕��������蓖�ĂĂ��邽�߂ɑS���ʂ̕����Ƃ��ĕ\������Ă��܂��܂��B�܂�UNIX�A���[�v����p�@�Ȃǂł͕������\������Ȃ��A�S���ʂ̕������\�������Ȃǂ̏�Q����������\�������邽�߁A���܂�g���ׂ��ł͂���܂���B���Ɋې�����n�V�S���i�^�̌����n�V�S�̂悤�ɂȂ��Ă���f�U�C���́g���h�j�Ȃǂ͎g��ꂪ���ł��B

��i��NEC���ꕶ���A���i��NEC�I��IBM�g�������@�iWindows95/98/NT4/2000/Me�Ȃǂł̕\�����\�ł��j
| ���F�@����12�N�����JIS X0212:2000�ł͈ꕔ�̋L���ނ�JIS�֒lj�����܂������AX0212���̂����y���Ă��Ȃ��̂Ŏ��p��͎g�p���ׂ��ł���܂���B |
| ���ې��� | �ې����Ȃǂ͕����̌��₷�������I�ɍ��߂邱�Ƃ��ł��邽�߁A�������ł���Ԉ���Ďg�p����P�[�X�c�v�͖��m�Ȃ̂ł������₿�܂���B�������AMacOS�iMacintosh�j�ł͑S���ʂ̕����ŕ\������Ă��܂��ȂǁA�{���͌݊����ɖR�����̂ł��B | (1)�A(2)�c I�AII�AIII�AIV�c <OL>�c�ő�p |
| �����w�L�� | ������JIS X0208-1983�����ő�ւ��ł��܂��̂ŁA��������g���܂��B | �����ʁځہ߁�����ő�p |
| ���i���j�Ȃ� | �v���|�[�V���i���t�H���g���g���A���F�̂Ȃ���ւ����\�ł��̂ŁA��͂蕁�i�����i���j���~���Ȃǂ̗l�ɒʏ�̕����Ƃ��ď����̂������ł��Bcm�Ȃ�ĉ��œ��ꕶ���ɂ���̂��Ȃ��c | �i���j�A�i��j�A�����A�������[�g���c�ő�p |
 ���C���^�[�l�b�g���[�U�[�v����
���C���^�[�l�b�g���[�U�[�v����
X0201 Kana�A�ʏ�ANK�J�i�i���p�J�i�j�̓p�\�R���Ƃ������t���o�ꂷ��\�N�ȏ���O���瑶�݂���W���K�i�ł����A�C���^�[�l�b�g��ł͐�Ɏg�p���Ă͂����Ȃ������ɉ������Ă��܂��B
���Ȃ݂Ƀp�\�R���ʐM���ł�1980�N��O����ANK�ł݂̂ŒʐM���Ă����قǂŁA�ʏ�͎g�p���Ă��ǂ������ƂȂ�܂��B
���p�\�R����p�����C���^�[�l�b�g�ڑ��Ƃ����Ӗ��ł͂���܂���B���ԈႦ�̖����悤�ɁB
| �⑫�P �F ���p�J�i���ĉ��H | ||||
| �@ | �Ƃ���Ŕ��p�J�i�Ƃ͌��� �wMS-DOS�Ȃǂ́i�����t�H���g��p����j���ŁA�c���䂪�P�F�P�̊����Ȃǂɑ��Ĕ����̉��������Ȃ��J�^�J�i�x
�Ƃ����Ӗ��ł����BJIS�EShiftJIS�R�[�h�ł̓f�[�^�ʂ��S�p�����̔����ł��B���m�ɂ�
�ƕ\������̂��K���ł��B ���������ݎ嗬��Windows��MacOS�iMacintosh�j�Ȃǂł͌��h���̗ǂ��v���|�[�V���i���t�H���g���g�p����邽�߁A���ۂ̑傫���́u���p�v�ł͂Ȃ��̂Œ��ӂ��K�v�ł��B ���̐}�͂ǂ������i�����p�����A���i���S�p�����̃J�^�J�i�ł��BMS-DOS�̕\���ł͖��炩�ɈႢ��������܂����AWindows�̕\���ł͋�ʂ�����Ȃ��Ă��܂��B�t�H���g�ɂ���Ă��S�������������܂���B
�������g�Ŕ��p�J�i����͂��Ă��܂��Ă��Ȃ���������������@�ł����A���_�u�J�v�┼���_�u�K�v���J�^�J�i����͂����Ƃ��ɁA�ꕶ���Ƃ��ĕ\����邩���Ƃ��ĕ\����邩�Ƃ����_���A��ԊȒP�Ȍ��������ł��B ���p�J�i�œ��͂���Ă���ꍇ�́A�Ⴆ�u�K�v�Ƃ��������Ȃ�u�J�v�Ɓu�J�v�̗l�ɓ��Ƃ��ĕ\�킳�܂��B���̂悤�ȏꍇ�́A�C���^�[�l�b�g��Ŏg�p���Ă͂Ȃ�Ȃ��������g���Ă���ƌ������ƂɂȂ�܂��̂ŁA���߂�K�v������܂��B |
|||
| �⑫�Q �F ���p�J�i���ĉ��̃C���^�[�l�b�g�Ŏg�����Ⴂ���Ȃ��́H | ||
| �@ | �@�@�����̃C���^�[�l�b�g�ł͏���7�r�b�g�����Ă������߂ɁA8�r�b�g�����i80�Ԉȍ~�̕����R�[�h�j�����܂������ł��Ȃ��V�X�e����20���I���ɂȂ��Ă����݂��܂��B����������邽�߂ɂ�8�r�b�g�����͔�������Ȃ�Δ�����X���ɂ���܂��B�i�Ƃ����Ă�Shift
JIS�ŏ����ꂽWeb�y�[�W���܂߁A�����ł�8�r�b�g�S���ł����j �����̊��o�ł͉��̂W�r�b�g�����ʂȂ̂�7�r�b�g���g���̂��Ǝv���邩������܂��A�����1960�`70�N��͋L���p�������[�����ɍ������������Ƃ�A�V�X�e����ʐM�n���̐M�������Ⴉ�������ƂɋN�����܂��B �����͉p�����̋L����ʐM�ɍŒ���K�v��7�r�b�g���L���ɓ��āA8�r�b�g�ڂ͐M�����m�ۂ̂��߂̃G���[�`�F�b�N�Ɏg�p���邱�Ƃ���������ł����B�܂����݂�8�r�b�g��1�o�C�g�Ƃ���R���s���[�^�[�����ł͂Ȃ�7�r�b�g��15�r�b�g�Ȃǂ�1�o�C�g�Ƃ����������[�\���̃R���s���[�^�[���������͂���܂���ł����B �@�@�Ƃ���� �u���p�J�i��8�r�b�g������C���^�[�l�b�g�ł͎g���Ȃ��v �܂������R�[�h��JIS�ȊO�iShift JIS��EUC-JP�j���g���Ă���Web�y�[�W�ł͊����R�[�h��8�r�b�g�ڂ��g���Ă���ł͂Ȃ����Ƃ�����肪����܂����A�W�r�b�g�̂܂ܑ��M���Ă��ǂ����i�����^�C���j�AMIME�Ȃǂ̕ϊ��@��7�r�b�g�ɂ��Ă��瑗�M���Ă��ǂ��̂œ��ɖ�肪����킯�ł͂���܂���B�������M���鑤���Ή����Ă����7�r�b�g���낤��8�r�b�g���낤�����͗ǂ������̂ł��B �@�@�ł́A���̎g���Ă͂����Ȃ��ƌ�����̂��Ƃ����Ύ��̓C���^�[�l�b�g�œ��{��������Ƃ��ɗp������ISO 2022-JP�iISO 2022�̃T�u�Z�b�g�A���{�Ŏg���Ƃ��̓R�R�܂őΉ����Ȃ����Ƃ����w�j�ƂȂ�j��US-ASCII�AJIS X0201 Latin�i�p���j�AJIS C6226-1978�AJIS X0208�����T�|�[�g���Ă��Ȃ��̂ł��B ���[����l�b�g�j���[�X��JIS �g�p�ł��镶���ɔ��p�J�i���܂܂�Ă��Ȃ��̂Ȃ�AISO 2022-JP���g���Ă��郁�[���A�l�b�g�j���[�X���ł͐�֎~�Ȃ̂������ł��܂��B ���p�J�i��8�r�b�g�R�[�h�Ƃ��������͊ԈႢ�ł��B�@�@�ł�WEB�͂Ƃ����ƁA���x��UNIX�̑��������p�J�i�ɑΉ����Ȃ��Ƃ������Ƀu�`������܂��BEUC-JP���g��UNIX�ł͔��p�J�i��0x8E??�Ƃ����R�[�h�ŕ\���ł���͂��ł����A�����̕������p�Ȃ̂�2�o�C�g�Ȃ̂͏������ώG�ɂȂ�Ƃ̗��R����A���p�J�i���T�|�[�g���Ă��Ȃ��V�X�e�������������̂ł��B�i���p�J�i��ϋɓI�ɃT�|�[�g���闝�R���Ȃ��������B�j �@�@����2�̖�肩��A�C���^�[�l�b�g�ł͔��p�J�i�̗��p�͐������ׂ��Ƃ̌��_�͌����Ă��܂������A�����܂łȂ�ǂ�����ʂɌ����闝�R�͊Ԉ���Ă���悤�ł��B �@�@����ɗ��j�������āA���[�U�[�����i���甼�p�J�i�𗘗p���Ă���p�\�R���ł��C���^�[�l�b�g���e�Ղɗ��p�ł���悤�ɂȂ�܂����BWindows95�̓o��ł��B �@ ���[�����M�ɗp����ISO 2022-JP�ŃT�|�[�g���镶����ɁA���p�J�i�͊܂܂�Ă��Ȃ����߁A���[���Ŕ��p�J�i���g�p�ł��Ȃ��n�Y�ł��B ���������[�U�[������Ĕ��p�J�i�����[���ő��M���悤�Ƃ����ꍇ�̓��[�U�[�Ɍx�����邩�A�����Ȃ��Έ�ԋ��e�ł�������ł���u�S�p�J�^�J�i�ɕϊ�����v�Ȃǂ��s���悢�̂ł���Microsoft Windows�̃v���O���}�[�͈Ⴂ�܂����B �@�@�C���^�[�l�b�g�ƍ��܂Ŗ����ł�����Windows�̃\�t�g�J���҂͑���̓s����S���������ăC���^�[�l�b�g�ɔ��p�J�i����������ȕ��@�ŗ����n�߂��̂ł��BISO 2022-JP�i7�r�b�g�R�[�h�j�œ����Ă���V�X�e���ɁAJIS8�����̃J�i�i8�r�b�g�R�[�h�j�𑗂���AMicrosoft Internet Mail�Ɏ����Ă̓��[����Shift JIS��EUC���g���Ă݂���A�V�r�b�g�������e�ł��Ȃ��V�X�e���̂��߂ɂ���MIME�̃w�b�_�[�ɓ��X��8�r�b�g�R�[�h���g���Ă���l�͂��͂≽���l���Ă�����Ƃ�����Ԃł��B ��MIME�c�C���^�[�l�b�g��Ŏx�ᖳ���f�[�^�𑗐M���邽�߂ɁA8�r�b�g�f�[�^��7�r�b�g�ɕϊ����邽�߂̕��� �L���҂���U�X�@����ă��[���\�t�g�ُ̈펖�Ԃ͉����̊Ԃɂ��R�b�\���Ɖ��P���ꂽ�悤�ł����AWEB��Ŕ��p�J�i�𐂂ꗬ��Windows���[�U�[�Ƃ����\�}�͍��ł��S�����P����Ă��܂���B �@�@�ł�����Ȏ��X�Ɛ��������Ƃ���ŁA�f�l�ɂ͗�������ƌ����Ă������Șb�ł�����A�Ƃ肠���� �@�@�@�@�u���p�J�i��8�r�b�g������C���^�[�l�b�g�ł͎g���Ȃ��v �Ɗȗ������Č�����̂ł��B |
|
�����A�p�\�R���ʐM��C���^�[�l�b�g�ŕ����𐳂�������M�ł���̂́A�ЂƂ��ɏ������p�����W���Ƃ����\�i�����R�[�h�\�j�ɏ]���ĕ����𐔒l�������i���m������Ă��邩��ł��B
�Ƃ��낪JIS�́u�����R�[�h�\�v�ɂ͖���`�̌��Ԃ�����A�p�\�R����[�v���Ȃǂ����ۂɍ�郁�[�J�[�́A�����֏���ȕ�����lj����Ă��܂��܂����B�������ɒlj������Ǝ��̕����͂��̋@��ł����\���ł��Ȃ��̂ŋ@��Ɉˑ����镶���c�܂�u�@��ˑ������v�A�u���ˑ������v�ƂȂ�܂��B
�{���A���ɂ͑��݂��Ȃ��͂��̕������ꕔ�@��E������ő��݂��Ă���ƌ������Ԃ͖{�i�I�ȃp�\�R���ʐM����ɓ����Ă���傫�Ȗ��ƂȂ�܂����B�����ē��R�A�ӎu�a�ʂ̏�Q�ƂȂ镨�Ƃ��Đ��Ԃ���������邱�ƂƂȂ�܂��B�p�\�R���ʐM���S���̎���ɂ͂���ɕ֏悵���C�W�����悭������i�ł����B
| ���[�J�[�E�@�� | �@��ˑ������̑��� | |
| NEC PC-9800 | NEC���ꕶ���i98�����ENEC�g���j NEC�I��IBM�g�������i�V�j |
|
| EPSON PC | ||
| SHARP X68000 | 1/4�p�����E�V�X�e���O���E2�o�C�g���p�Ȃ� | |
| APPLE | Macintosh | KT7�ˑ������Ȃ� |
| IBM�݊��@ | DOS/V�� | IBM�g������ |
| MSX�d�l�@ | MSX�����i���p�Ђ炪�ȁA���p�L�������j | |
| NTT DoCoMo | i-mode | i-mode�����ii-mode�G�����j |
| �F | �F | |
����ł͋@��ˑ������ɂ��āA���܂�Windows���[�U�[�ɒm���Ă��Ȃ��f�B�[�v��(?) ������Ă݂܂��傤�B
�}�C�N���\�t�g�W���L�����N�^�[�Z�b�g�Ƃ�Microsoft����߁AWindows3.0���̗p���������Z�b�g�̂��Ƃ�
|
��NEC PC-9800/EPSON PC-x86�V���[�Y�̂݁iWindows���[�U�[�ɂ͖��W�j
���{�d�C�iNEC�j��1997�N���܂ň�ʂɔ̔����Ă���PC-9800�V���[�Y�i���ݎ嗬��PC98-NX�V���[�Y�Ƃ͈Ⴂ�܂��j�ƁA�G�v�\�����̔����Ă����݊��@EPSON PC�V���[�Y�ŗL�̕����ł��B1985�`1997�N���܂ł̍����ő吨�͂ł�����PC-9800�V���[�Y�͗ǂ����������@��ˑ��������̕�ɂł��B

���̋@��i���������h�j�̃��[�U�[��PC-9800�V���[�Y��ڂ̓G�ɂ��镗�������邽�߂ɁA�����̃p�\�R���ʐM�Ȃǂł͂����Εs�тȑ����̎�ɂȂ�܂����B�Ȃ���i�̔��p�����́u2�o�C�g���p�v�Ƃ��������ŁANEC�̃n�[�h�E�G�A�ł͗e�ՂɎ����\�ł����Ă��A�ʏ�̏����n�ł͔��Ɋ�قȊT�O�ł��BWindows�ł��T�|�[�g�͂��Ă��܂���B
[ �����R�[�h�@ | �����R�[�h�A | �����ꗗ�\ | INDEX ]
�Ȍ�쐬��
�@ JIS�̔��ɂ��Č��Ă݂�ƁA1978�N�ɍ����������A1983�N�ɐ������𐧒肵�܂����B1995�N�ȍ~�ɔ̔�����Ă��鐻�i��JIS X0208-1990�ɏ����Ƃ��Ă���̂���ʓI�ł��̂ŁA�}�̍����E���̕����͎g�p���Ă��ǂ��ƍl�����܂��B
�@ ������2000�N��JIS X0213:2000�Ő��肳�ꂽ���������́A�g�p����ɂ͎��������ł��B���̋K�i�͐��肳�ꂽ����ŁAJIS X0213:2000�ɑΉ�����Windows���v�ȃ\�t�g�E�G�A�������ɔ��\���炳��Ă��Ȃ��̂�����ł��B�i���̑O��Windows���������Ή����Ȃ��S�z������܂���(��)
�j
�@ ����Ɍ��݂̃C���^�[�l�b�g�Ŏg�p����Ă���ISO 2022-JP�ł́AJIS X0213�͑z�肳��Ă��炸�A����ɗ������Ƃ̓��[���ᔽ�ɓ�����܂��B�܂�META�^�O��
charset=Shift_JIS �iiso-2022-jp�j�ȂǂƂ��Ĕ��M����͖̂{�����猾���Θ_�O�ł��B

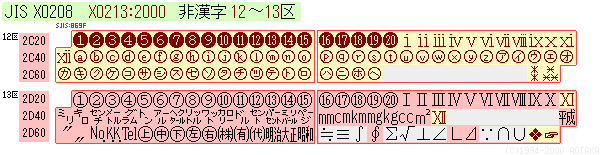
| ���� | �ŏ��i78JIS�j����̕����A�@��ˑ����͊F�� |
| �� | �VJIS�i83JIS�j�ŐV�K��`���ꂽ�����A���͋@��ˑ����͖����ƌ��ėǂ� |
| ���� | 2000JIS�ŐV�K��`���ꂽ�����A����ł͑唼����Ή� ��2000�N10�����݂ł͊eOS�̑Ή����F���̂��߂Ɏg�p���Ȃ������ǂ� |
| 13��̍��� | NEC���ꕶ���A�ɂ߂ė��p���͍������@��ˑ������L��iMacintosh���j ���s���N�n��2000JIS�ō̗p�A�D�F�͕ۗ��扻 |
�@ 1990�N��A��ʂɍL�����p���ꂽ�p�\�R���̒���NEC PC-9800�V���[�Y������JIS X0208-1983�i�VJIS�j�ȍ~��S������܂���ł����B�VJIS����ȑO�ɔ������Ă����V���[�Y�Ƃ̌݊����̐����L�͂ł����A�ő���NEC������Ȃ������u�VJIS�ŐV���ɒ�`���ꂽ�����v�͒��炭�u�@��ˑ������v�Ɠ����̈������Ȃ���Ă��܂����B
�@ DOS�̎���̓L�����N�^�[�W�F�l���[�^�[�Ƃ����@�B���i�ɂ�蕶�����\������Ă������߂ɕς��悤���Ȃ������Ƃ������������܂��B���ꂪ�\�t�g�E�G�A�ŕ\�����s��Windows3.1�ł͋@��ɊW�Ȃ��VJIS���T�|�[�g���܂����BWindows���S���ɂȂ������ƂȂ��Ă͋@��ˑ����͂Ȃ��Ȃ����ƌ��č\���܂���B

�@ ���{�H�ƋK�i�iJIS�j�ł́A�K�i���V������������邽�тɌÂ��ł͖����ƂȂ�܂����A�@�B�ɑg�ݍ��܂ꂽROM��\�t�g�����R�ɍX�V�����킯���Ȃ��A�ǂ����Ă��V���̋K�i�����p����邱�ƂɂȂ�܂��B���̂��߂ɐV���̔����ȍ��ق����ƂȂ邱�Ƃ�����܂��B����C6226�i��X0208�j��1983�N�����͍��ق��傫���A�l�������Ȃǂւ̉e����A�����̕K�v���Ȃǂő傢�ɋc�_����邱�ƂƂȂ�܂����B
| ���K�i�� | ���� | ��������� | �K�肵�Ă��镶�� |
| JIS X0201 | ANK | C6220-1969 | �w7�r�b�g�y��8�r�b�g�̏������p�����������W���x 1�o�C�g�����Z�b�g�i�����锼�p�p�E���E�J�i�j |
| C6220-1976 | |||
| X0201:1997 | |||
| JIS X0208 | ��JIS | C6226-1978 | �w7�r�b�g�y��8�r�b�g�� 2�o�C�g�������p�����������W���x JIS�� JIS��ꐅ������ JIS������� |
| �VJIS | C6226-1983 | ||
| X0208-1990 | |||
| X0208:1997 | |||
| JIS X0212 | JIS�⏕���� | X0212-1990 | JIS�⏕���� |
| JIS X0213 | 2000JIS | X0213:2000 | JIS��O���������E��l�������� |
�����ł́A�Ƃ��Ɉ�ʐl�ɂ���肪�[����X0208�i��C6226�j�ɂ��ĉӏ������Ő������܂��B�L���ɂ��Ă͕\������邩����Ȃ�����ڗđR�Ȃ̂ʼn��̕��̐}�����Ă��������B
�� �F X0208�Ƃ��Ċg�����ꂽ�킯�ł͂Ȃ��BX0208�g���p�ɍ��ꂽ�K�i�ł���
�@ �܂����Ȃ��ƂɃ��[�J�[�̕��j�ɂ��A�ǂ�JIS�K�i�̂ǂ̕������̗p���邩���������������ԂŁA���}�̂悤�Ƀ��U�C�N��悵�Ă��܂��B�p�\�R���ʐM�ł�2�E8��E84��̒lj��L����78/83����ʂ���X���ɂ���܂����A���ۂɂ͒P����78��83��90���Ɛ�̂Ă��܂���B
��DOS�S������̋@��ɂ�镶����̈Ⴂ
83 �c JIS X0208-1983�i�VJIS�j�ȍ~ �� �c �G�v�\��PC����ł͋�JIS�A�VJIS���V�X�e���ݒ�ŕύX�ł��܂��B �� �c IBM DOS J5.0/V�ł́AIBM�g�������Əd������ʁi�ے�^224C�j��i����ā^2268�j�͖���`�ɂȂ��Ă���B ��83JIS�Ə����������ɂ��Ă͐��Y�����ɂ��90JIS�����̂��̂�����܂��iWin3.1�݂͂��90JIS�j |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
�@ �@��ˑ������ł͂���܂��A���p�́��i�~�L���j��ASCII�ł́_�i�o�b�N�X���b�V���j�ƒ�`����Ă���A���ɂ���Ă̓o�b�N�X���b�V���Ƃ��ĕ\������邱�Ƃ�����܂��B���������{�ꂪ��������ł���ɂ�������炸�o�b�N�X���b�V���ŕ\�����鏈���n������̂ō�����̂ł��B
�@ �����ASCII���e���Ń��[�J���C�Y���邽�߂ɍ��ꂽ�K�i�uISO 646�v�ɂ��0x5C���܂�12�����͊e���Ŏ��R�ȋL���ɒu�������ėǂ����ƂɂȂ��Ă��邽�߂ɋN���鍬���ł��B�h�b�g�v�����^�[�Ȃǂ̐������ɍڂ��Ă���\������Ɗe���̈Ⴂ��������܂��B
| �R�[�h | 0x23 | 0x24 | 0x40 | 0x5B | 0x5C | 0x5D | 0x5E | 0x60 | 0x7B | 0x7C | 0x7D | 0x7E |
| IRV �i����ASCII�Ɠ����j |
�� | �� | �� | �m | �_ | �n | �O | �M | �o | �b | �p | �` |
| JIS �i�K�i�\�̎��`�j |
�� | �� | �� | �m | �� | �n | �O | �M | �o | �b | �p | �| |
| NEC �iPC-9800�AEPSON PC�j |
�� | �� | �� | �m | �� | �n | �O | (�M) | �o | �b �b |
�p | �` |
�@ �Ȃ��`���_�u�`�v�ƃI�[�o�[���C���u�P�v�����̖��ƕ����āA�قȂ�Ǝv������ł���l�����܂����A����͎��ۂ̌����ڂ͈���Ă��Ă�ISO 646�AX0201���Ɋ��K�I�ɓ��������Ƃ��Ĉ����Ă��܂��B�i�ŐV��X0201:1997�ł́A���̂��ƂɌ��y����悤�ɂȂ�܂����B�j�@���̂悤�ɓ���̕����Ȃ̂Ɏ��`�������ɈقȂ��Ă��鎖���A���`�̗h��Ƃ����܂��B�i�`���_�ƃI�[�o�[���C���͌����ڂ͖����ꒃ�傫���ł����c�j
�@ ��ʐl���ӎ�������ł͂���܂��A�ʐM�Ȃǂ�JIS�R�[�h���g�p�����Ƃ��̃G�X�P�[�v�V�[�P���X�ɊԈႢ�����������A���ƂȂ邱�Ƃ�����܂��B
�@ ���i������{�ł�US-ASCII�܂���JIS X0201�p���AJIS X0201�J�i�AJIS X0208�Ƒ�R�̕����K�i�p���Ȃ��ƕ����������܂���B���{�l��4�̃X�N���v�g���g�����Ȃ������I�o�C�����K�������i�p���Ɛ����E�������E�J�^�J�i�E�����j���Ƃ�����ł��傤�B
�@ �����̕����K�i��芷����ׂ̍��ۓI��@��ISO 2022�ŁAJIS�R�[�h�̃G�X�P�[�v�V�[�P���X�͂��̋K�i�ɏ��������ł��B������������J���҂��������F�����Ă��Ȃ������肷�邱�Ƃ�����܂��B
�@ �܂�NEC������ɈقȂ�G�X�P�[�v�V�[�P���X���g���Ă�����AEMCA�iISO 2022�̕������Ǘ����Ă���c�́j�ւ̐\�����ɁA�\�z��JIS�̋K�i���������Ă��܂������ׂɊԈ���ĕ\�L����Ă��镶�������݂���Ȃ�Ď�������܂��i�j
| JIS�� ��ւ� |
�����̏ꍇ | JIS7�̏ꍇ | |||
| �����̊J�n (KI) |
ASCII�̊J�n (KO) |
�⏕�����̊J�n | 1�o�C�g �J�^�J�i |
ASCII�̊J�n | |
| ISO 2022 ���� |
78JIS�p�@ESC $ @ 83JIS�p�@ESC $ B |
ESC ( B ESC ( J |
ESC $ ( D | SO (0x0E) ESC ( I |
SI (0x0F) ESC ( B ESC ( J |
| NEC JIS �i�Ǝ��j |
ESC K | ESC H | �@ | �@ | �@ |
| �R�����g�͐VJIS���̗p���Ă��鏈���n�Ō����Ƃ��̂��̂ł��B |
�lj����ꂽ�� ��JIS���̎��`�i�ړ��j
JIS SJIS JIS SJIS
3646 8BC4 �� �� 7421 EA9F �
4B6A 968A �� �� 7422 EAA0 �
4D5A 9779 �y �� 7423 EAA1 �
6076 E0F4 �� �� 7424 EAA2 �
7425 EAA3 � ���z�i515B/997A�j�ّ̈̎���lj�
7426 EAA4 � �����i5F66/E086�j�ّ̈̎���lj�
��ꐅ�� ���
3033 88B1 �� ���� 724D E9CB ��
3229 89A7 �� ���� 7274 E9F2 ��
3342 8A61 �a ���� 695A E579 �y
3349 8A68 �h ���� 5978 9D98 ��
3376 8A96 �� ���� 635E E27D �}
3443 8AC1 �� ���� 5E75 9FF3 ��
3452 8AD0 �� ���� 6B5D E67C �|
375B 8C7A �z ���� 7074 E8F2 ��
395C 8D7B �{ ���� 6268 E1E6 ��
3C49 8EC7 �� ���� 6922 E541 �A
4128 9147 �G ���� 6C4D E6CB ��
445B 92D9 �� ���� 5464 9AE2 ��
4557 9376 �v ���� 626A E1E8 ��
456E 938E �� ���� 5B6D 9E8D ��
4573 9393 �� ���� 5E39 9FB7 ��
4676 93F4 �� ���� 6D6E E78E �
4768 9488 �� ���� 6A24 E5A2 �
4930 954F �O ���� 5B58 9E77 �w
4B79 9699 �� ���� 5056 98D4 ��
4C79 96F7 �� ���� 692E E54D �M
4F36 9855 �U ���� 6446 E2C4 ��
�����`�ύX�݂̂̊����͏ȗ����܂��i1983�N�����ł�244�����A��ςɂ�萔�͑O��j
