■_
行ってきました。 connpass-第八回ありえるえりあ勉強会 ~PyPyのキホンの気








三番目に発表した彼は、この質問をした人だったらしい

一つ前へ
2012年1月(上旬)
一つ後へ
2012年1月(下旬)
connpass-第八回ありえるえりあ勉強会 ~PyPyのキホンの気 >>> 発表内容(各35分程度) 「次世代言語 Python による PyPy を使った次世代の処理系開発」 登壇者: @shomah4a 「PyPy における静的解析」 登壇者: @cocoatomo 「PyPyとJITコンパイラ - Introduction to PyPy and JIT compile」 登壇者: @chlere
発表資料はこの辺
いろいろメモったけど、たぶんスライド見ればわかると思うので転記はしないでおこう (面倒くさいし :)。
推薦図書/必読書のためのスレッド 65 877 デフォルトの名無しさん [sage] 2012/01/19(木) 13:51:15.34 ID: Be: コンピュータアーキテクチャで、これは読んどけって本あったら教えてください。 878 デフォルトの名無しさん [sage] 2012/01/19(木) 13:52:11.89 ID: Be: ヘネパタ 879 デフォルトの名無しさん [sage] 2012/01/19(木) 14:03:35.94 ID: Be: >>878 やっぱヘネパタですかい? 量がちょっと多いから、初心者には敷居が高いような感じも。 880 デフォルトの名無しさん [sage] 2012/01/19(木) 14:19:52.67 ID: Be: ヘネシー&パタパタママ 881 デフォルトの名無しさん [sage] 2012/01/19(木) 15:55:03.03 ID: Be: 先にパタヘネだろ 882 デフォルトの名無しさん [sage] 2012/01/19(木) 16:28:01.48 ID: Be: 定量的アプローチの方は下地がないと何かいてあるかわからんぞ 883 デフォルトの名無しさん [sage] 2012/01/19(木) 17:55:12.56 ID: Be: >872 アルゴリズムとその実装ぐらいしか知らないとみた。 実際にそれらを使ってデータを処理するまでがサイエンス。 884 デフォルトの名無しさん [sage] 2012/01/19(木) 18:48:22.85 ID: Be: パタヘネと言えば 第4版がでるけどどうなのかね 885 デフォルトの名無しさん [sage] 2012/01/19(木) 19:15:48.00 ID: Be: 出るっていうかもう出てるでしょ。 入門書として手堅い良書って位置付けは変わらないと思うけど、 値段がまた上がってしまった…。 886 デフォルトの名無しさん [sage] 2012/01/19(木) 20:14:18.33 ID: Be: 第3版は何か薄っぺらくなったなあと思ったけど また厚くなったのか 887 デフォルトの名無しさん [sage] 2012/01/19(木) 21:50:39.81 ID: Be: よし、ヘネパタ、読んでみる!! 888 デフォルトの名無しさん [sage] 2012/01/20(金) 05:20:00.61 ID: Be: まずはパタヘネとヘネパタの区別はできてるか? 889 デフォルトの名無しさん [sage] 2012/01/20(金) 08:42:28.15 ID: Be: そんな暗号みたいな呼び方せずに構成と設計、定量的アプローチって主題の一部を使えばいい
君たちにとっては簡単かもしれないけど僕にとっては難しいんだ!察してくれ!頼む!
「クリエイティブ・エンジニアの未来 ~受託とサービスの垣根を越えて~」に参加してきました
次回からバッハを始める。英語では「ばーっく」だ。
あとバグるとヒールで踏まれます。
不満たらたら
そういや、ブーマーが殿堂入りの資格を失ったとか(年齢だかエントリ回数の制限で)? なんじゃそりゃという気がしてならないなあ。 いや、資格に制限つけるというのはいいんだけど、彼が殿堂入りしないってどういうことよという
SICP is being taught again at MIT | Hacker News It's too bad that this is just a compressed sampler course and that they are not reinstating the original class. I took the equivalent course at Berkeley, which also taught SICP with Scheme, and I can't possibly imagine a better introductory Computer Science class, for 2 reasons: もともとのコースがそのまま復活したのではなく、compressed sampler なのは too bad であると。 First, as is stated everywhere else, SICP is a beautiful book and it does an amazingly fun and efficient job teaching you many, many fundamental topics in CS, and more than that it teaches you how to think and develop good intuitions for it. SICP をこれでもかというくらい持ち上げています Second, and maybe an opinion you haven't heard, teaching the class in Scheme is a huge benefit, and anyone who says the opposite just plain sucks. Pardon my coarseness, but so many kids who start out their college career are little shits who think they know everything about programming and that taking an introductory class is beneath them. I've heard that sentiment expressed almost verbatim, along with people listing off all the projects they've done in python and java and whatnot. When the professor (no longer Brian Harvey unfortunately!) starts teaching the class in Scheme they all shut their grubby little mouths and actually listen and try to learn something. The naysayers don't understand that the class isn't about programming, it's about computer science, and just the beauty of seeing that this weird functional language you've never seen before can be used to do everything from taking derivatives elegantly to implementing it's own interpreter to developing a query language or an OO language, etc, goes a long way in illustrating the malleability, openness, and sheer potential of Computer Science to new students who should be learning just that.Looks like Brian Harvey is retiring, but before he does, he's working on a self-paced version of 61A, which will also include chapter 5 of SICP! (Cal, historically, has always only taught chapters 1-4, to the point, IIRC, of having a special SICP published without chapter 5). http://www.cs.berkeley.edu/~bh/61a.html I hope this is made available to the public, as it's a bit like discovering a long-lost director's cut ending to a much-loved film.
↓ 講座の名前を見てたりするといろいろ興味をひかれるものが
SIPB IAP 2012 Activities SIPB Classes A Tale of Two Lisps Advanced C Caffeinated Crash Course in Computer Forensics Caffeinated Crash Course in PHP Caffeinated Crash Course in Ruby Debathena Trainees Git Will Make Your Life Better Introduction to LaTeX Introduction to Ruby on Rails Programming Java Programming Perl Programming Python Programming in C Programming in Haskell Programming in Postscript The GNU Debugger Getting Your Feet Wet with WordPress Web Programming in Python with Django New Emacs for Beginners New Modern Programming Language Design New Software Project Management New Secure Coding in C New Code Injection for Fun and Profit New x86 Assembly Primer for C Programmers New The Internet Shouldn't Work: Networking 101 New Debian/Ubuntu Bug Squashing Party New Writing Kernel Exploits Co-Sponsored Classes Get Your Ham Radio License Caffeinated 6.001 Advanced NetBeans Desktop Application Development Google Map APIs & Google Fusion Tables The C++ 2011 Standard: What's New? Mobile Virtualization: Smartphones with Multiple Personalities Embedded Systems Design Competition Relational Database Management System & Internet Application Programming Introduction to C and C++ Intro to Software Engineering in Java
おそらく関西人のかなりは、ちくわぶというものを見たことも聞いたこともないだろう。私も大阪に住んでいた頃は全く知らなかった。
Looking back, looking forward | 6guts So, 2012 is here, and here's my first Perl 6 post of the year. Welcome! :-) Looking Back 2011 brought us a faster Rakudo with vastly improved meta-programming capabilities, the first work on exploring native types in Perl 6, the start of a powerful type-driven optimizer and many other bits. It also took me to various conferences and workshops, which I greatly enjoyed. I'd like to take a moment to thank everyone involved in all of this! This was all great, but slightly tainted by not managing to get a Rakudo Star distribution release out based on a compiler release with all of these improvements. I'd really hoped to get one out in December. So what happened? Simply, there were a certain set of things I wanted to get in place, and while many of them got done, they didn't all happen. While the compiler releases are time based – we do one every month – the distribution releases are more about stability and continuity. By the time I headed back to the UK to spend Christmas with family, we were still missing a some things I really wanted before a Star release was done. Given the first thing that happened when I started relaxing a little was that I immediately got unwell, I figured I should actually use my break as, well, a break – and come back recharged. So, I did that. So, let's try again So, the new goal is this month. I'm happy to report that in the week since I've got back to things, one of the things I really wanted to sort out is now done: Zavolaj, the native calling library, now does everything the pre-6model version of it did. In fact, it does a heck of a lot more. It's even documented now! It's also far cleaner; the original implementation was built in the space of a couple of days with mberends++ while I was moving apartment, and was decidedly hacky in places. The missing bits of the NativeCall library were important because they are depended on by MiniDBI, and I really didn't want to ship a Rakudo Star that can't connect to a database. So, next up is to make sure that is in working order. I'm not expecting that to be difficult. That aside, there were some things to worry about in Rakudo itself. I've dealt with some of those things in the last week, and perhaps the one important remaining thing I want to deal with before Star is a nasty regex engine backtracking related bug (I've been hoping pmichaud++, the regex engine guru, might appear and magic it away, but it seems it's going to fall on my plate). But overall, we're well on track to cut the Star release this month. What's the direction for the year ahead? During 2011, Rakudo underwent a significant overhaul. It was somewhat painful, at times decidedly not much fun, but ultimately has been very much worth it: many long standing issues have been put to rest, performance has been improved and many things that were once hard to do are now relatively easy or at least accessible. I think it goes without saying that we won't be doing any such wide-ranging overhaul in 2012. :-) The work in 2011 has opened many doors that we have yet to walk through, and 2012 will see us doing that. At a high level, here's what I want: Less bugs, more stability: mostly this is about continuing to work through the ticket queue and fix things, adding tests as bugs are fixed to ensure they stay fixed. Better error reporting: there are things in STD, the Perl 6 standard grammar, that allow it to give much more informative error reports on syntax errors than we often can in Rakudo today. I want us to bring these things into Rakudo. Additionally, there's plenty of improvements to be made in runtime errors. Furthermore, I want to expand the various bits of static analysis that I have started doing in the optimizer to catch a much wider range of errors at compile time. Run programs faster: this process is helped by having decent profiling support these days. There's a lot more to be done here; the optimizer will help, as will code generation improvements. Compile programs faster: this will come from more efficient parsing and greatly improving the quality of the code NQP generates (NQP is the language we write much of the compiler in) Shorter startup time: this mostly involves finishing the bounded serialization work up. I think the best way to describe this stuff is “fiddly”. Use less memory: Rakudo has got faster in no small part thanks to being able to understand its performance through profiling. Our understanding of its memory consumption is much more limited, which makes it harder to target improvements. That said, I've some good guesses, and some ideas for analyzing the situation. More features: while being able to do the things Rakudo can do today faster and with less bugs would give a very usable language for quite a lot of tasks, there's still various features to come. In particular, Rakudo's support for S05 and S09 needs work. VM Portability: we've made good progress towards being able to make a serious stab at this over the last year, while at the same time also managing to perform vastly better on Parrot too. With help from kshannon++, I'm currently working on completing the switch to QRegex (a regex engine with NFA-powered LTM, and written in NQP rather than PIR), which should carry on a pattern of simultaneously increasing performance and portability. Beyond that will be an overhaul of our AST and code generation, with the same goal in mind. So, lot's of exciting things coming up, and I look forward to blogging about it here. :-) A way to help There are many ways to get involved, depending on what you're interested in. One way is to take a look at our fixed bugs that need tests writing. At the time of writing, just short of 100 tickets are in this state. No guts-y knowledge needed for this – you just need to understand enough Perl 6 (or be willing to learn enough) to know what the ticket is about and how to write a test for it. Drop by #perl6 for hints. :-)
プログラミング言語の未来について
Whiley | Connecting the Dots on the Future of Programming Languages
Yesterday, I serendipitously came across two things which got me thinking about the
future of programming languages:
The first was an excellent article entitled “Welcome to the Hardware Jungle” by
Herb Sutter. This article is about the coming advent our multicore overlords. Whilst
this might sound like something you've heard before, it's actually well worth the
read. His argument is that heterogeneous massively-multicore computing is fast
becoming the norm, and there is no turning back. I found the article quite scary, as
I can't imagine programming in the extreme environment suggested. I also have to
question whether everyday applications will really benefit from massive multicore. But,
clearly, I can see that quite a few will.
The second was the following (short) youtube video of Simon Peyton Jones and Eric
Meijer discussing the space of programming languages:
Now, the question is: how do they connect together? Well, essentially, I think the “Nirvana”
space the Simon talks about is exactly the space we need to deal with the Hardware Jungle.
In other words, I think it's the space most suitable for distributed and parallel computing.
(略)
コメントのひとつ↓
How do some of the Prolog-like languages fit in here? Prolog isn't purely functional of course, but in practice (in my experience) most of the computational code written in it is. The major exception is a few common tricks for memoising results. I imagine that the same techniques useful for parallelising Haskell could be applied to logic languages. But I am quite ignorant there.
Lua で i18n したいんだけど。
web development - Lua - How to do Internationalization? - Stack Overflow
I built a Lua web application and it's become clear that I need to begin internationalizing
("i18n") it for my overseas customers.
In Lua, what's the best way to internationalization my application?
I realize this is a significant undertaking, especially since some of my display is hard
coded in HTML templates and some data fields are in my currently US-english oriented database.
Any guidance would be appreciated.
テーブル使ってごにょごにょやるようです。
手元不如意
『Coders at Work』はいい本なので、思いのままにまとめてみた。
もっとシンプルに言えば、怖がらずにちゃんと挨拶ができるかどうかだと思います。怖そうに見えても、実際に怖い人はそうそういないです。
Perl の文字クラスの動作
ハングアップの日々 (2012/01) にもある正規表現ライブラリの性能比較。
drwxr-xr-x viewvc/viewvc 0 2010-07-21 05:29 reb/ -rw-r--r-- viewvc/viewvc 786 2010-07-21 04:17 reb/Makefile -rw-r--r-- viewvc/viewvc 176 2010-07-21 02:45 reb/pattern.txt drwxr-xr-x viewvc/viewvc 0 2010-07-20 03:19 reb/boost/ -rw-r--r-- viewvc/viewvc 544 2010-07-20 03:19 reb/boost/Makefile -rw-r--r-- viewvc/viewvc 471 2010-07-20 03:19 reb/boost/test-iostream.cc -rw-r--r-- viewvc/viewvc 577 2010-07-20 03:19 reb/boost/test.cc drwxr-xr-x viewvc/viewvc 0 2010-07-21 04:03 reb/glib/ -rw-r--r-- viewvc/viewvc 349 2010-07-21 04:03 reb/glib/Makefile -rw-r--r-- viewvc/viewvc 609 2010-07-21 04:03 reb/glib/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 03:21 reb/onig/ -rw-r--r-- viewvc/viewvc 386 2010-07-20 03:21 reb/onig/Makefile -rw-r--r-- viewvc/viewvc 583 2010-07-20 03:21 reb/onig/test-posix.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 03:23 reb/pcre/ -rw-r--r-- viewvc/viewvc 543 2010-07-20 03:23 reb/pcre/Makefile -rw-r--r-- viewvc/viewvc 515 2010-07-20 03:23 reb/pcre/test-cpp.cc -rw-r--r-- viewvc/viewvc 583 2010-07-20 03:23 reb/pcre/test-posix.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 01:29 reb/perl/ -rwxr-xr-x viewvc/viewvc 189 2010-07-20 01:29 reb/perl/test.pl drwxr-xr-x viewvc/viewvc 0 2010-07-20 11:32 reb/python/ -rwxr-xr-x viewvc/viewvc 321 2010-07-20 11:32 reb/python/test.py drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:39 reb/re2/ -rw-r--r-- viewvc/viewvc 432 2010-07-20 00:39 reb/re2/Makefile -rw-r--r-- viewvc/viewvc 513 2010-07-20 00:39 reb/re2/test.cc drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:25 reb/regex/ -rw-r--r-- viewvc/viewvc 290 2010-07-16 11:48 reb/regex/Makefile -rw-r--r-- viewvc/viewvc 579 2010-07-20 00:25 reb/regex/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:25 reb/regex-old/ -rw-r--r-- viewvc/viewvc 298 2010-07-16 11:48 reb/regex-old/Makefile -rw-r--r-- viewvc/viewvc 118949 2010-07-16 11:48 reb/regex-old/regex.c -rw-r--r-- viewvc/viewvc 18723 2010-07-16 11:48 reb/regex-old/regex.h -rw-r--r-- viewvc/viewvc 579 2010-07-20 00:25 reb/regex-old/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:25 reb/regexp9/ -rw-r--r-- viewvc/viewvc 300 2010-07-16 11:48 reb/regexp9/Makefile -rw-r--r-- viewvc/viewvc 27502 2010-07-16 11:48 reb/regexp9/regexp9.c -rw-r--r-- viewvc/viewvc 3875 2010-07-16 11:48 reb/regexp9/regexp9.h -rw-r--r-- viewvc/viewvc 569 2010-07-20 00:25 reb/regexp9/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-21 02:45 reb/tcl/ -rw-r--r-- viewvc/viewvc 296 2010-07-21 02:45 reb/tcl/Makefile -rw-r--r-- viewvc/viewvc 663 2010-07-21 02:45 reb/tcl/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:25 reb/tre/ -rw-r--r-- viewvc/viewvc 355 2010-07-16 11:58 reb/tre/Makefile -rw-r--r-- viewvc/viewvc 583 2010-07-20 00:25 reb/tre/test.c drwxr-xr-x viewvc/viewvc 0 2010-07-20 00:25 reb/trex/ -rw-r--r-- viewvc/viewvc 297 2010-07-16 12:38 reb/trex/Makefile -rw-r--r-- viewvc/viewvc 587 2010-07-20 00:25 reb/trex/test.c -rw-r--r-- viewvc/viewvc 17076 2010-07-16 12:38 reb/trex/trex.c -rw-r--r-- viewvc/viewvc 2224 2010-07-16 12:38 reb/trex/trex.h drwxr-xr-x viewvc/viewvc 0 2010-07-21 05:29 reb/v8/ -rw-r--r-- viewvc/viewvc 399 2010-07-21 05:29 reb/v8/test.js drwxr-xr-x viewvc/viewvc 0 2010-07-21 04:17 reb/xpressive/ -rw-r--r-- viewvc/viewvc 436 2010-07-21 04:17 reb/xpressive/Makefile -rw-r--r-- viewvc/viewvc 624 2010-07-21 04:17 reb/xpressive/test.cc
↑のファイルと↓の対応がよくわからない(xpressove みたいに一目瞭然のものもあるけど) のだけど、
Library/program Algo UTF-8 Perl Light POSIX URI Email Date Sum3 URI|Email boost::regex (1.42) BT ? Yes No No 5.44 1.82 1.15 8.41 9.84 boost::xpressive (1.42) ? ? Yes No No 3.72 1.51 1.22 6.45 7.80 Glib (2.24.1) ? ? Yes No No 1.08 0.84 0.79 2.35 18.02 onig-posix (5.9.2) BT Yes Yes No Yes 0.34 0.44 0.41 1.19 10.89 PCRE-posix (8.10) BT Yes Yes No Yes 0.67 0.39 0.54 1.60 13.48 RE2 (2010-07-19) FSA Yes Yes No No 0.57 0.56 0.55 1.68 0.58 Regex (Mac, 10.6.4) ? ? No No Yes 1.18 0.54 1.28 3.00 19.66 Regex (NCBI, ?) BT No No Yes Yes 7.21 9.83 3.45 20.49 22.35 regexp9 (20100715) FSA Yes No Yes Similar 1.90 2.12 0.95 4.97 4.55 Tcl (8.5) ? Yes No No Similar 2.17 1.73 1.52 5.42 3.66 TRE (0.8.0) FSA ? No No Similar 4.34 2.42 1.73 8.49 8.57 T-Rex (1.0) ? No No Yes No 4.39 6.45 2.45 13.29 9.35 egrep (GNU, 2.5.1) ? Yes No NA NA 0.07 0.08 0.10 0.25 0.16 gawk (3.1.8) ? Yes No NA NA 1.43 1.40 1.38 4.21 1.43 Javascript V8 (2.3.1) ? ? ? NA NA 2.30 2.57 1.17 6.04 3.70 nawk (20070501) FSA No No NA NA 1.40 1.40 1.40 4.20 1.40 Perl (5.8.9) BT Yes Yes NA NA 0.63 0.59 0.52 1.74 10.61 Python (2.6.1) ? Yes No NA NA 6.37 10.19 2.18 18.74 16.03
-rw-r--r-- viewvc/viewvc 118949 2010-07-16 11:48 reb/regex-old/regex.c
の先頭にあるコメントをみると以前使われていた GNU の regex で、
GNU grep が 2.5.1 だから同じものなんですよね。
とはいえ GNU grep は二つ正規表現エンジン抱えていて、後方参照使ってない場合なんかでは
もうひとつのほう(dfa.c)が使われます。
にしたって、成績違いすぎだろ・・・
↑の比較表にあるもので言うと、gawk は新しいほうの GNU regex を使っています。
この新しいほうのGNU regex は比較記事のページ末尾にあるもうひとつの表の
Library/Program URI Email Date URI|Email re2 (20100719) 0.54 0.56 0.50 0.64 regex (glibc 2.3.6) 3.12 3.96 0.39 3.91 regexp9 (20100715) 1.74 2.09 0.97 4.25 tcl (8.4) 1.56 1.26 1.09 2.72 gawk (3.1.5) 0.47 0.43 0.30 0.36 egrep (GNU 2.5.1) 0.09 0.05 0.10 0.16 nawk (20070501) 0.94 0.92 0.92 0.92 perl (5.8.8) 0.62 0.56 0.62 9.93 python (2.5) 4.26 7.00 1.58 10.66
regex (glibc 2.3.6) と基本的には同じもの。のはず。 でも数字が違いすぎる気がするなあ。こっちも。
Rory - Neopoleon : Die, Hungarian notation... Just *die*. で reddit が盛り上がり。
Die, Hungarian notation... Just *die*. : programmingWasn't the problem that Hungarian Notation just badly misused by a load of people? The point was supposed to be to preface variable names with something reasonably application-specific and meaningful, (so for example v for a vertex, n for a normal, etc) not cluttering up the source with i for an int (redundant as the article says, as the IDE provides this) or even worse o for an object. That said, if I had one bullet I would reserve it for people who write variable names starting "my", "our" or "the" in professional code. At least try and make it look like it's not been cobbled together out of example code.
↑これが発端
この寒い時期の寝落ちはとても危険
ふかーいネストをどうにかしよう。というお話。
Reducing Code Nesting - Eric Florenzano's Blog Reducing Code Nesting Jan 1st, 2012 "This guy's code sucks!" It's something we've all said or thought when we run into code we don't like. Sometimes it's because it's buggy, sometimes it's because it conforms to a style we don't like, and sometimes it's because it just feels wrong. Recently I found myself thinking this, and automatically jumping to the conclusion that the developer who wrote it was a novice. The code had a distinct property that I dislike: lots of nesting. But the more I think about it, the more I realized that it's not really something I've heard discussed much. So let's talk about it. I'm going to first talk about what I mean by nesting, why I think it's a bad quality, and then I'm going to go over some tricks I've learned over the years to reduce it. What do I mean by code nesting, and why is it bad? It's easier to demonstrate rather than talk about it. This is what I mean by deep code nesting, with my apologies for the contrived example: def get_cached_user(user_id=None, username=None): """ Returns a cached user object either by their user_id or by their username. """ user = cache.get_user_by_id(user_id) if not user: user = cache.get_user_by_username(username) if not user: user = db.get_user_by_id(user_id) if not user: user = db.get_user_by_username(username) if not user: raise ValueError('User not found') cache.set_user(user, id=user.id, username=user.username) return user
論より証拠ということでどのように変えていくのかは元記事へどうぞ :)
Zed 再び登場。
Learn C The Hard Way | Hacker News I recently started working through Learn C the Hard Way, and after doing a few chapters I wrote down what I liked about it in a notebook. Digging it up, here it is: "Why I like Learn C the Hard Way: - Opinionated. I think opinionated textbooks are great because they limit their scope and focus on something. Rather than being an authoritative reference (who uses text references anymore?), it's a framework for learning. - Emphasizes reading and editing which contributes to overall understanding - It's lean. Goes with opinionated, but it's nice that it doesn't repeat what's been done, but sends you there directly, i.e. don't waste time writing about "strcmp", send me to "man 3 strcmp" since I need to get familiar with it anyway." Disclaimer: I'm a bit new to low-level coding, so feel free to point out why these reasons for liking the text might be naiive.oblique63 I too just started reading this one. For me, my first foray into 'low-level' programming was during my freshman year in a CS101 course that used C++. That first course on it's own wasn't too bad, but the subsequent 'introductory' courses for more C++ and Data Structures + Algorithms were just terrible. I couldn't absorb anything useful from them because I was just overwhelmed with the constant bombardment of Segmentation Faults everywhere. Poor teachers + high learning overhead as a result of using a low-level language, just made me want to stray as far away as possible from ever using a 'C-langage' again. If it wasn't for me discovering Python around the same time, I probably would've just given up and pursued music or audio engineering instead. (略) Thanks Zed!zedshaw > I noticed that the things he makes you look up on your own are generally specific > enough that it makes the task of filtering out all the nonsense much easier than if > you were researching it on your own. That's my trick. I actually go googling and make sure that it's something you can find easily with a little nudge. Part of the goal of my books is to teach basic research skills so you can survive on your own. Glad you got that. And, you're welcome. I'm still working on it, but feel free to fill out comments with problems you hit.jc-denton Yeah that dumbass Zed Shaw, looking at not even half done freetard stuff is a waste of time. There is K&R and a lot of good contributions to stackoverflow [1]. [1] http://stackoverflow.com/questions/4810664/how-do-i-use-arra...zedshaw Nothing is more enjoyable than watching idiots like you imagine that the world is a fully formed perfect thing that can't possibly be a work in-progress. I watch you guys never put anything out there for fear that someone will think it's just not quite perfect enough. Meanwhile, I crap things into my toilet better than anything you'll make mostly because I put stuff up while I'm working on it so I get immediate feedback. To me, the new artist is about showing the process, not just the final work.
とりあえずふたつだけ。 訳しづらいフレーズを連発しているのだけはわかったw
たしかに不注意といえばそれまでだが、こういう不注意を誘発するような仕様はまずい。
Rubyist には必須の知識(のひとつ)だそうです→ 泳ぐやる夫シアター やる夫で学ぶ第一次世界大戦 第二十五夜「カンブレーの戦い~出撃!陸上大艦隊!~」
そいや南北戦争はやる夫シリーズにあったっけ? あれも結構いろいろあるんだけど(歴史群像の特集で知った程度)
昨日例のアレで池袋のジュンク堂に行ったわけなんですが、 さらにコンピューター関係の洋書が減っていてぐんにゃり。 まあ値段から言うとAmazonさんとは野口さんで数人違っちゃったりする場合がありますしねえ。
とはいえ自分も電書を買うパターンのが多くなってきたしなあそもそも。
なんか気になる記事が
InfoQ: PowerShell 3の紹介 PowerShell 3は、現在CTPの Windows Management Framework 3.0の一部としてリリースされる。 DLRベースであることから離れてみると、ワークフローの改善、より簡単なシンタックス、資格 情報の委任、堅牢なセッションなど、多くの新しい機能が追加されている。 (ry) このバージョンにおけるいくつかの新しい機能は - PowerShellワークフロー 中断やシャットダウンなどのネットワーク障害からセッションを自動的に回復する 認証情報のセットで委任されて実行できるコマンド群 単純化された言語シンタックス コマンドレットの検索と自動的なモジュール読み込みの改善 ODataを通じたRESTful Webサービスをコマンドレットとして公開できる機能 ISEコマンドアドオン インテリセンスとコードスニペット 新しいDHCP用のコマンドレット 簡単にWebから返されたXMLを簡単に操作できるInvoke-RestMethod。PowerShell MVPのDoug Fink氏は、ブログでサンプルを提供している。 モジュールの自動読み込み Web アクセス – ブラウザ/モバイルデバイスを使って、リモートからPowerShellにアクセス デフォルトパラメータ値
で、単純化された言語シンタックスとやらのリンク先を見てみますれば
Windows PowerShell Version 3 Simplified Syntax | Keith Hill's Blog Windows PowerShell Version 3 Simplified Syntax Posted on October 19, 2011 Windows PowerShell version 3 introduces a simplified syntax for the Where-Object and Foreach-Object cmdlets. The simplified syntax shown below, eliminates the curly braces as well as the need for the special variable $_. C:\PS> Get-Process | Where PM -gt 100MB ... C:\PS> Get-Process | Foreach Name ... The intent of this “syntax” is to make it easier for folks get started with PowerShell. Compared to the commands below, I can see the value of the simplified syntax: この「構文の」意図は、PowerShellの入門者に対してもっと易しくするためです。 以下のコマンドラインと比べてみると、単純化された構文の価値がわかりました。 C:\PS> Get-Process | Where {$_.PM -gt 100MB} ... C:\PS> Get-Process | Foreach {$_.Name} ... When folks are first learning PowerShell, the special variable $_ is one of those mental model hurdles they have to get over. The simplified syntax feature of V3 seems to generate a fair amount of controversy (is it really necessary, doesn't this just complicate things more, etc). Regardless of where you stand on the simplified syntax it is useful to understand how it works. 初めて PowerShell を学んだ人にとっては、特殊変数 $_ が越えなければならない心理的なハードルのひとつです。 この単純化された構文機能は論争を引き起こしたようです (それは本当に必要なものであるとかいっそう複雑にするものではないとか)。 あなたがこの単純化された構文に対してどのような立場にあるかには関係なく この構文はどのように動作するのか理解するのに有用なものです。 Given that it appears to be a simplified expression syntax you might think this required a change to the PowerShell parser's grammar but you would be wrong. It turns out that the simplified syntax is implemented by additional parameter sets – lots of additional parameter sets. In fact, for every operator supported, there is an additional parameter set to support that operator. Let's see this with the Where-Object cmdlet by listing out all of its parameter set names: C:\PS> Get-Command Where-Object | Select -Expand ParameterSets | Format-Table Name Name ---- EqualSet ScriptBlockSet CaseSensitiveGreaterThanSet (略) CaseSensitiveInSet NotInSet CaseSensitiveNotInSet IsSet IsNotSet (以下略)
140字に収まる範囲でライフゲーム。らしい。 Playing With Mathematica » Blog Archive » Life in 115 characters
Here's the code in a form that you can copy and paste.
ListAnimate[ArrayPlot/@ CellularAutomaton[{224,{2,{{2,2,2},{2,1,2},
{2,2,2}}},{1,1}},{RandomInteger[1,{9,9}],0},90]]
欲しいなあ。
古い記事が元で盛り上がる reddit
What is the single most effective thing you did to improve your programming skills? (old Stack Overflow discussion) : programming What is the single most effective thing you did to improve your programming skills? (old Stack Overflow discussion) (stackoverflow.com)
面白い回答があったかもしれないけど量にめげて見つけられませんでした :)
古い記事が掘り起こされたシリーズその2。 取り上げられた記事は2008年あたりのもの。
Want to Write a Compiler? Just Read These Two Papers. : programming Want to Write a Compiler? Just Read These Two Papers. (prog21.dadgum.com)I believe that if you are a programmer, you should at least try to write a compiler, with your own lexer and parser. It doesn't have to be a complex language compiler, you can simply take very small subset of any language (something like Pascal without any libraries and only Integers shall be fine). Why? Well: it is not that hard as it seems to be, it is great fun, it provides great satisfaction if you actually get it working, and - which is most important - it will teach you a lot.I believe that everyone in the filed should read this book: "The Elements of Computing Systems" It contains a series of projects that range from hardware design, writing an assembler, a compiler and then finally an operating system. After having done this myself, I find that almost everything in the field is easier to understand and work with.That looks awesome! Thanks. Much of the content looks likes it's free online hereAnd you should learn assembly. You don't need to know how to write a server in assembly. You need to know how programs and programming works at the lowest level. I program in JavaScript/C#. I've wanted to write my own language, and I made a basic interpreter with variables and commands, but I was always baffled at how programs keep their state with user-written functions and the concept of scope. Then I took assembly 101, and I felt like a moron. It's the simplest damn thing under my nose the entire time: the stack. Duh. It changes the way you think about things, and for someone who's had previous programming experience, assembly was a breeze.writing a compiler can be easy, just don't target c++ or x64 with your first try. define your own input ( for example some subset of c) define your own output ( a toy vm interpreting simple instructions) write a tokenizer ( a function which splits your source into logical parts "int val = 1" is changed to [identifier "int"] [identifier "val"] [equals "="] [int_value "1"] write a parser which takes tokens and builds a tree ( the above becomes allocate space for an "int" named "val" and assign 1 to "val") walk this tree and output your instructions (instructions can be generated both going down and up) What makes modern compilers so complex complex input (c++) complex output (and many targets) complex optimisation many options (man gcc)
JavaScript の不思議な動作
回答のひとつに出てきた表が結構力作?
arrays - Why does [1,2] + [3,4] = "1,23,4" in JavaScript? - Stack Overflow I wanted to add the elements of an array into another, so I tried this simple sentence in our beloved Firebug: ある配列の複数の要素を別の(これも複数の)要素と加算したいと思いました。 そこで、次のような簡単なセンテンスを Firebug で試してみたのですが [1,2] + [3,4] It responded with: 結果はこうなりました "1,23,4" What is going on? いったい何がおきたのでしょうか?
ふむ。
>jsshell js> [1,2] + [3,4] 1,23,4 js>
おお。
そして解説
The + operator is not defined for arrays.
配列に対する + 演算子は定義されていません。
What happens is that Javascript converts arrays into strings and concatenates those.
Javascript が配列を文字列へと変換して、それらを連結したのでそのような結果になったのです。
Update
Since this question and consequently my answer is getting a lot of attention I felt
that in addition to the insightful stuff posted by Jeremy Banks it would be useful to
have an overview about how the + operator behaves in general.
So, here it goes.
Excluding E4X and implementation-specific stuff, JavaScript has 6 built-in data types:
undefined
boolean
number
string
function
object
Note that neither null nor [] is a separate type - both return object when fed to typeof.
However + works differently in either case.
null も [] も独立した型ではないことに注意してください。
どちらも typeof を使ったときに返ってくるオブジェクトです。
しかし + はこれらに対して異なる働きをします。
That's right - JavaScript has no primitive arrays as such; only instances of a class
called Array with some syntactic sugar to ease the pain.
Adding more to the confusion, wrapper entities such as new Number(5), new Boolean(true)
and new String("abc") are all of object type, not numbers, booleans or
strings as one might expect. Nevertheless for arithmetic operators Number and Boolean
behave as numbers.
Easy, huh? With all that out of the way, we can move on to the overview itself.
Different result types of + by operand types
-------------------------------------------------------------------------------------------
| undefined | boolean | number | string | function | object | null | array |
-------------------------------------------------------------------------------------------
undefined | number | number | number | string | string | string | number | string |
boolean | number | number | number | string | string | string | number | string |
number | number | number | number | string | string | string | number | string |
string | string | string | string | string | string | string | string | string |
function | string | string | string | string | string | string | string | string |
object | string | string | string | string | string | string | string | string |
null | number | number | number | string | string | string | number | string |
array | string | string | string | string | string | string | string | string |
-------------------------------------------------------------------------------------------
* this applies to Chrome 13, Firefox 6, Opera 11 and IE9. Checking other browsers and versions
is left as an exercise for the reader.
Note: As pointed out by CMS, for certain cases of objects such as Number, Boolean and
custom ones the + operator doesn't necessarily produce a string result. It can vary
depending on the implementation of object to primitive conversion. For example var o =
{ valueOf:function () { return 4; } }; evaluating o + 2; produces 6, a number,
evaluating o + '2' produces '42', a string.
To see how the overview table was generated visit http://jsfiddle.net/4EjXd/
C言語で2つ文字列の連結して、1つの文字列にするプログラム(関数)を書けるでしょうか?
これ、日本の大手新聞社だとどうなるのか誰か試算してほしい。
社内のメンバーで集まって、お互いの開発環境を紹介したりする勉強会をやっていました。資料をつけて発表する形式でなく、本当に見せあいっこをする感じ。 (略) みんなも、ちゃんとした勉強会じゃなくて、こういうのやればいいと思います。
なむさん(id:numberock)とast15さん(id:ast15)と、伴読部という活動をすることになりました。 「併」ではなく「伴」です。伴走から取りました。ではこれは一体どういうものかというと、端的には以下の通りです。
また、新たに翻訳者のブラックリスト機能を搭載した。ユーザーは質の悪い翻訳をした翻訳者をブラックリストに指定することで、次回以降の依頼の際に通知を送らないようにできる。
名古屋でも始まったようで。 TAPL-nagoya 勉強会 #1 - 名状しがたきチラシの裏
アドエスの乗り換え先これにしちゃおうかしらん W-ZERO3復活か?京セラの3GとPHSのハイブリッドAndroidが認証通過!! – すまほん!! でもあんどろさん×2台ってのもなあ(^^;

行ってきました。 ざっと各月の上位20位のリストを見て感じたのは、 言語の入門書がほとんどないなあということでしょうか。 以前のデータと突き合わせて確認するのが面倒なので間違ってるかもしれませんが、 これまでとは違う傾向のような? しかし RubyKaigi 効果すげーw

実は(各月の)ベスト20に入ってこなかった本に面白いものが



この時計、本来の終了時間が近くなったところで、
高橋会長の目前に移動されました。
この写真の時点で15分オーバーで、さらに20分弱…
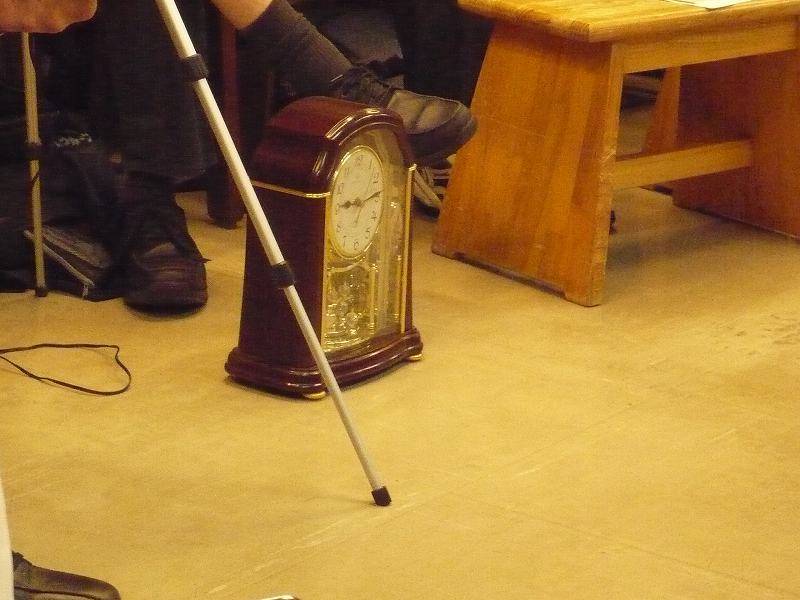
こういう本でも同じ値段(450円)つけるのね
(この二箇所だけではもちろんなくて、結構なページ数にこういった書き込みがありました。
就職活動の面接対策に使っているような文章もあったんだけどどうなったんだろうか)。


2冊で500円セールでなきゃ買わなかったよw
そういやとあるJava入門書の著者から返ってきた返事についてまだ書いてなかったような。 ということを 「値渡しか参照渡しか」という二分論は混乱の元 - 西尾泰和のはてなダイアリー で紹介されている発言で思い出したり。 まあどうでもいいっちゃいいんですが
めったに起きないことのための対策はどうあるべきか。その対策に対する合理化が問題を引き起こすという意味では、津波による原発事故の問題と、根っこは同じ問題ではないかとも思う。
> インドリさんご自身は挙げられた4つのどれだとお考えですか? 第5タイプの観察者です。 私の場合、外部の利害関係者として参加するという立場上そうなります。
買った



坂の上の雲は毎年でてたのね。
ワイルド7は作曲が川井さんだったで :)
Firefox の アドオンの xpi をインストールじゃなくてダウンロードだけしたいんだけど どうすればいいんだろう? 以前はできた覚えがあるんだけど、インターフェースが変わっててよくわからん。
あとで読む
【入門】Common Lisp その8【質問よろず】 750 デフォルトの名無しさん [sage] 2012/01/12(木) 15:38:06.07 ID: Be: http://blog.livedoor.jp/s-koide/archives/1846185.html >2003年ニューヨークのConferenceではものすごく感動的なトークをし マッカーシーは2003年にどんなトークをしたのでしょう? 752 デフォルトの名無しさん [sage] 2012/01/12(木) 20:43:49.62 ID: Be: >>750 comp.lang.lispでも話題になったから検索してみて。 John "Practical" McCarthy でたどれると思う。 しかしそのページILCのIがInternetになってるな。 近くの人教えてあげて。 753 デフォルトの名無しさん [sage] 2012/01/13(金) 16:04:07.76 ID: Be: どうもありがとうございます https://groups.google.com/group/comp.lang.lisp/browse_thread/thread/6c75cae46f065843/f06272a6e41dfdfa?hl=ja&lnk=gst&q=John+%22Practical%22+McCarthy#f06272a6e41dfdfa Anton van Straatenさんの発言をまとめると… マッカーシーはチャーチのラムダ計算の考えをlispに部分的に取り入れた、 万が一ラムダ計算をlispのデザイン全体に持ち込んでいたら 実用的なプログラミング言語というものを誤って推し進めたかも、 純粋な型無しのラムダ計算にひどく捕らわれていたかもしれない で、実際のところは無名関数を設けるラムダの表現の意味を拝借したのだ、と lispを開発していたときマッカーシーは チャーチの本のコピーを持ってはいたが最初から最後まで読んだわけでは無かった 飛ばし読みをしていた そのおかげで上のようなデメリットが避けられた lispを作った本人がlispの限界とその理由をかいつまんで解説したと 理解したのですが、これでいいでしょうか 754 デフォルトの名無しさん [sage] 2012/01/13(金) 16:41:45.59 ID: Be: Yコンビネータで再帰定義、再帰実行とか、 理論的整合性の泥沼にはまらずに済み、 実践的な言語設計をすることが出来たってことでしょ。 もともと数式評価するFORTRANライブラリ書いていたわけだから、 下手すりゃSucc(Succ(Zero))とか別の方向行っちゃうもんね。 755 デフォルトの名無しさん [sage] 2012/01/13(金) 17:18:30.24 ID: Be: 結局、動的スコープ以外はほぼ間違いなかったわけだしな
Freeware Downloads にあるのってソースが見当たらないんだけど、 配布されてるのそのままなんだろうか?
Microsoft (R) COFF/PE Dumper Version 7.10.3077
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file gawk.exe
File Type: EXECUTABLE IMAGE
Section contains the following imports:
KERNEL32.dll
(略)
msvcrt.dll
(略)
MSVCP60.DLL
46D340 Import Address Table
46D104 Import Name Table
0 time date stamp
0 Index of first forwarder reference
0 btowc
1 mbrlen
2 mbrtowc
5 wcrtomb
7 wctob
9 wctype
msvcrt.dll
(略)
2C0 setlocale
(略)
2F5 wcscoll
2F9 wcslen
socket 関連のは見当たらなかった。 setlocale があるし、wcs* もあるんで、locale 設定に応じてマルチバイト文字対応はする? でも msvcrt の setocale って ja_JP.UTF-8 みたいな文字列は対応してたっけ? corbieのブログ:Windows版gawk選び のコメント欄を見ると受け付けているっぽいんだけど。
次に strings でどんな文字列があるかをチェック
libgcc_s_dw2-1.dll __register_frame_info libgcj-11.dll _Jv_RegisterClasses __deregister_frame_info Mingw runtime failure:
などとというアヤシゲなものを発見。
Mingw で決まりかな。 配布されているやつは Mingw ではそのままビルドできるからそれで作ったのを配布している ってことなんだろうか。 しかし locale の環境変数はわからんなあ。
これも翻訳されるのかな
InfoQ: Interview and Book Review: Programming Concurrency on the JVM Interview and Book Review: Programming Concurrency on the JVM Posted by Srini Penchikala on Jan 10, 2012 In his latest book Programming Concurrency on the JVM, author Venkat Subramaniam talks about the concurrency techniques using different JVM programming languages such as Java, Clojure, Groovy, JRuby and Scala. He also discusses topics like Software Transactional Memory (STM) and Actor-based Concurrency. InfoQ spoke with Venkat about strategies and design approaches for programming concurrency on JVM and hardware capabilities to achieve concurrency. (略) InfoQ: There are other books on the concurrency topic. How is this book different from other books? 並列処理を取り上げた本はほかにもありますが、この本はそれらとどのように違うのでしょうか? Venkat: If your interest is totally focused on the JDK solutions to concurrency, then I suggest that you look no further than the "Java Concurrency in Practice" by Brian Goetz, et. al. My objective in the "Programming Concurrency on the JVM" book is to take the readers well beyond the solutions offered directly in the JDK. (略) InfoQ: What should the Java developers and architects keep in mind when they are working on making their applications concurrent? Venkat: I have an entire chapter dedicated to this question in the book. Developers (programmers, architects, ...) are in desperate need for programming API that will help them reap the benefits of the powerful hardware they have on hand today. Fortunately, there are quite a few options to choose from, if they're willing to look beyond the facilities offered only in the JDK. Concurrency choice is orthogonal to the language choice. It is not about which programming language we use, but which library we select to use. There are some general guidelines we can follow—avoid shared mutable variables and design the application to avoid thread-safety issues rather than struggle to ensure thread-safety. (略)
タイトルが挙げられている本で、↓は日本語版もある
(higepon 効果で復刊したやつ)。


もうひとつ挙げられているほうはどうなんだろうか。
2011年9月にでているらしいのだけどどこか翻訳を進めてたりする?
Pragmatic Bookshelf だしなあ

電書もあるよねえこの出版社なら The Pragmatic Bookshelf | Programming Concurrency on the JVM 22ドルか。 買っちゃうか。
あの本のこととかあの本のこととか書きたいのだけど まとめている余裕ががががが。
near/far はよーーーく覚えているんだけど、 LONG の反対で SHORT ってポインターあったっけ?
Windows プログラミング #2 LPSTR は文字列へのポインタです。接頭に "P" or "LP" がつくデータ型 はポインタとして定義されています。LPSTR は "Long Pointer of STRing" の略です。 Windows がまだ 16 ビットだったころ、32 ビットのポインタを "Long Pointer"、16 ビットのポインタを "Short Pointer" と呼んでいました。今はすべてのポインタは 32 ビットなのですが、"LP" はそのころの名残として残っています。 ちなみに LPSTR は、次のように定義されていると考えてよいでしょう。 typedef char *LPSTR;
short pointer って使った覚えないんだよなあ。 一応 3.1 あたりから Windows プログラミングはやってるんだけど。
ReadInt16 Method (IntPtr, Int32) using namespace System; using namespace System::Runtime::InteropServices; void main() { // Create an unmanaged short pointer. short * myShort; short tmp = 42; // Initialize it to another value. myShort = &tmp; // Read value as a managed Int16. Int16 ^ myManagedVal = Marshal::ReadInt16((IntPtr) myShort, 0); // Display the value to the console. Console::WriteLine(myManagedVal); }
Implementing DoProcessOutput Retrieve a sample from the input buffer. You do this by dereferencing the input data pointer and storing the result in a variable of type int. For 16-bit audio, you must recast the BYTE pointer to a short pointer to handle the greater audio sample precision. Once you have the value, you can immediately increment the pbInputData pointer so that it points to the next sample. The following examples demonstrate this:
↑ みたいな使い方はしても(サイズが短い)ポインターを意味するようなのは? と思いつつさらに探してみると
c - Difference between LPVOID and void* - Stack Overflow Can I use void* instead of LPVOID in c? Or LPVOID perform some special functionality then void*There is no LPVOID type in C, it's a Windows thing. And the reason those sort of things exists is so that the underlying types can change from release to release without affecting your source code. For example, let's say early versions of Microsoft's C compiler had a 16-bit int and a 32-bit long. They could simply use: typedef long INT32 and, voila, you have your 32-bit integer type. Now let's go forward a few years to a time where Microsoft C uses a 32-bit int and a 64-bit long. In orfer to still have your source code function correctly, they simply change the typedef line to read: typedef int INT32 This is in contrast to what you'd have to do if you were using long for your 32-bit integer types. You'd have to go through all your source code and ensure that you changed your own definitions. It's much cleaner from a compatibility viewpoint (compatibility between different versions of Windows) to use Microsoft's data types. In answer to your specific question, it's probably okay to void* instead of LPVOID provided the definition of LPVOID is not expected to change. But I wouldn't, just in case. You never know if Microsoft may introduce some different way of handling generic pointers in future that would change the definition of LPVOID. You don't really lose anything by using Microsoft's type but you could be required to do some work in future if they change the definition and you've decided to use the underlying type. You may not think pointers would be immune to this sort of change but, in the original 8088 days when Windows was created, there were all sorts of weirdness with pointers and memory models (tiny, small, large, huge et al) which allowed pointers to be of varying sizes even within the same environment.but in the old days, way back when ...Back on 16-bit 8086, long (far) pointers and short (near) pointers were different: the former was a 32-bit value of segment+offset, and the latter was a 16-bit value of offset (thus could only point to within the same segment). Nowadays there's no distinction between long pointers and any other kind of pointer. – ephemient Jan 1 '10 at 5:57"long/short pointer" is misleading ("far/near" is clearer); it has nothing to do with the datum being pointed at, but rather the pointer representation. A 16-bit system with segmented addressing can access more than 2^16 bytes of address space, but anything outside of the current segment cannot be accessed without a segment prefix. x86-32 and x86-64 use flat addressing (PAE is weird and sorta gives you longer physical addresses, but virtual addresses are still 32 bits), so this is no longer relevant, but the naming was established with Win16. – ephemient Jan 1 '10 at 6:07© 2012 stack exchange inc; user contributions licensed under cc-wiki with attribution required↑の long/short pointer の使い方は最初の使い方と同じですね。 んで、書籍でもあった模様↓
この辺の情報に詳しい方見てたらよろしく。
How do I divide a number by 100? Probably not this way. : programming で、200以上コメントがついているからどんな内容なのだと見てみれば
java - Moving decimal places over in a double - Stack Overflow So I have a double set to equal 1234, I want to move a decimal place over to make it 12.34 So to do this I multiply .1 to 1234 two times, kinda like this double x = 1234; for(int i=1;i<=2;i++) { x = x*.1; } System.out.println(x); This will print the result, "12.340000000000002" Is there a way, without simply formatting it to two decimal places, to have the double store 12.34 correctly?Here's a link to the original article "What Every Computer Scientist Should Know About Floating-Point Arithmetic"© 2012 stack exchange inc; user contributions licensed under cc-wiki with attribution required
がっかりだよっ!w
1行書くごとに、え本当にHaskellで書いていいの?いいの?って思い悩みながら作ってます。いやもう他の言語を使ってる人に申し訳ない。
さらにWarren氏は、以前2つのコンパイラ(C# と VB)はC言語で書かれており全てのコンパイラ開発者はC言語のエキスパートであったが、コンパイラを書く言語エキスパートは必要でなくなる。と述べている。
↑これ、原文は↓なんだけど、なんか違うような? but 以下は訳文とは違うことを言っているように思うのだけど
Warren added “...previously both compilers [C# and VB] were written in C, so all the compiler developers were C experts” but not necessarily experts in the language they were writing the compiler for.
眠気に負ける日々
deconstruct ってぴたりとくる日本語がないような
deconstructの意味 - 英和辞典 Weblio辞書 deconstruct 【動詞】 1 分解する方法によって、解釈する(テキストまたはアートワーク) (interpret (a text or an artwork) by the method of deconstructing)
deconstructの意味 - 英和辞典 Weblio辞書 deconstruct 【動詞】 【他動詞】 1 〈…を〉分解する,解体する. 2 〈文学作品などを〉脱構築 (deconstruction) の方法で分析する.元はこれなんですけどね ↓
55 Deconstructing "K&R C" Chapter 55 Deconstructing "K&R C" When I was a kid I read this awesome book called "The C Programming Language" by the language's creators, Brian Kernighan and Dennis Ritchie. This book taught me and many people of my generation, and a generation before, how to write C code. You talk to anyone, whether they know C or not, and they'll say, "You can't beat " K&R C" . It's the best C book." It is an established piece of programmer lore that is not soon to die. 子供だった頃にわたしは Brian Kernighan and Dennis Ritchie の書いた "The C Programming Language" と呼ばれるすばらしい本を読みました。 この本でわたしや同世代の多くの人、さらに前の世代の人たちも C でプログラムをどのように書くかを教わりました。 あなたが誰かと話したとき、その人がCを知っているかどうかには関係なく こう言うでしょう "You can't beat "K&R C" . It's the best C book." (K&Rを disるなんてできないよ。あれは最高の C の本だ) と。 It is an established piece of programmer lore that is not soon to die. これはすぐに死に絶えることはないプログラマー伝承の established piece です。 I myself believed that until I started writing this book. You see, "K&R C" is actually riddled with bugs and bad style. Its age is no excuse. These were bugs when they wrote the first printing, and the 42nd printing. I hadn't actually realized just how bad most of the code was in this book and recommended it to many people. After reading through it for just an hour I decided that it needs to be taken down from its pedestal and relegated to history rather than vaunted as state of the art. わたし自身、がこの本を書き始めるまでは K&R がバグや bad style と格闘しているものだと 信じていました。その時代は言い訳にはなりません。 それは first printing の時点からあるバグで、42nd printing にもあります。 わたしは K&R にあるコード大部分がとてもひどいコードであり この本を多くの人に薦めることが良くないことであるのか認識していませんでした。 一時間ばかりかけて読み通した後で決心しました it needs to be taken down from its pedestal and relegated to history rather than vaunted as state of the art. #どうにもいい訳文がでてこないのだけど、「持ち上げられすぎている」今の状況を #変えてどうこうということですよね。たぶん。 I believe it is time to lay this book to rest, but I want to use it as an exercise for you in finding hacks, attacks, defects, and bugs by going through "K&R C" to break all the code. That's right, you are going to destroy this sacred cow for me, and you're going to have no problem doing it. When you are done doing this, you will have a finely honed eye for defect. You will also have an informed opinion of the book's actual quality, and will be able to make your own decisions on how to use the knowledge it contains. In this chapter we will use all the knowledge you've gained from this book, and spend it reviewing the code in "K&R C" . What we will do is take many pieces of code from the book, find all the bugs in it, and write a unit test that exercises the bugs. We'll then run this test under Valgrind to get statistics and data, and then we'll fix the bugs with a redesign. (略)
本として完成したら誰か訳さないかなー とかつぶやくとブーメランが飛んできそうな気がする
そして↑が Hacker News で話題に
よく見ていくと、zed 本人らしき書き込みがいくつも
Deconstructing "K&R C" | Hacker News tba I'm confused. What is the "defect" in K&R's "copy(char to[], char from[])" function? The author notes that "the second this function is called...without a trailing '\0' character, then you'll hit difficult to debug errors", but no function with that signature could possibly work in this case. The built-in "strcpy" function has the exact same limitation. Does the author have a problem with it as well? Null-termination is a fundamental concept of C strings; there's no reason to shield C students from it. The other example of "bugs and bad style" in this "destruction" of K&R C is a minor complaint about not using an optional set of braces. I hope the remainder of the [incomplete] chapter demonstrates some actual bugs in the book's code, because it currently doesn't live up to the first paragraph's bluster.mechanical_fish The built-in "strcpy" function has the exact same limitation. Does the author have a problem with it as well? Yes. From the linked chapter: we avoided classic style C strings in this book From an earlier chapter on strings: The source of almost all bugs in C come from forgetting to have enough space, or forgetting to put a '\0' at the end of a string. In fact it's so common and hard to get right that the majority of good C code just doesn't use C style strings. In later exercises we'll actually learn how to avoid C strings completely. This is the author's opinion, of course – it's from a book, that should go without saying – but it's not as if the idea of avoiding C strings in general, and "strcpy" in particular, is an oddball or unique point of view. See e.g.: http://stackoverflow.com/questions/610238/c-strcpy-evilpeapicker "the majority of good C code just doesn't use C style strings..." Nice. In the 23 years I have worked on C language products, I've never worked on "good C code" by this definition. The cool thing about this guys book, I guess, is that by avoiding all the things about the language he doesn't like, any reader will be wholly unprepared for C in the Real World after this book.mechanical_fish This chapter is explicitly teaching people what the author's idea of bad C code is: It has them read some, then tells them specifically what the gotchas are, then asks them to code up test cases for the flaws and run them through Valgrind. Where's the "avoiding" here? And which of the skills being exercised - imagining what kinds of bad things could happen, writing executable test cases, detecting segfaults - are not useful in the real world?zedshaw That's basically the point of this chapter. It's getting people to think like a hacker and try to break the code in unintended ways. That makes them better programmers and helps when avoiding common mistakes in C code. Using K&R to do this is to give people a set of known good C code samples and show how even those can be broken and misused.angersock It's a nice strawman, right? Especially when he points out that the original code, in context, is perfectly fine. His later complaint about the assignment-in-if statement is certainly something shared by modern C programmers (see compiler warnings about same), but it perfectly fits the original style and accomplishes its task. His criticisms seem to be rooted so far in stylistic issues and in taking the code out of context (design context, usage guarantees, etc.). Then again, how are you to nerdbait while still being fair to original sources?zedshaw My criticisms are only partially stylistic, but also that people copy this code to other situations and it breaks. So, I'm showing them why it only works in that one specific context and how to break the code.zedshaw > but no function with that signature could possibly work in this case. This is the source of the bugs in C. People write functions that only work given all calls to them are never changed, which is absurd. Good modern C code involves trying to protect against bad usage and adding defensive checks. So yes, the built-in strcpy is crap which is why most competent C doesn't use it except in a few rare cases where it's required. And this does demonstrate actual bugs in the code. I wrote a test case that causes it, which incidentally is a common bug in C code called a buffer overflow. It's because of code examples like this that get copied to other situations that we have these defects.geophile Huh? My C programming is in the distant past, so I might be forgetting. But strcpy does assume a terminal zero, doesn't it? E.g., http://linux.die.net/man/3/strcpy. It sounds like you are talking about strncpy or memcpy.zedshaw Yes, strcpy is almost universally understood as a security problem. In fact, here's a nice regex to apply to some C code to find buffer overflows: LC_ALL=C egrep '[^_.>a-zA-Z0-9](str(n?cpy|n?cat|xfrm|n?dup|str|pbrk|tok|_)|stpn?cpy|r?index[^.]|a?sn?printf|byte_)' src/*.c Taken from the really well researched and secure andhttpd: http://www.and.org/and-httpd/#secure Run that regex on some C code, then go look at how the inputs to those functions are used, and then you can probably create some of your own buffer overflows. It's like magic.
そして reddit でも
Deconstructing "K&R C" - Zed Shaw : programming I wish Linus Torvalds would write a book about C programming. I'd like to read that.Would you read "Zen and the Art of Graphics Programming" by John D. Carmack II? ;)Yes I would, I love reading Carmack's stuff. The only works of Torvald's that I have read have been flames ... Maybe someone should produce an anthology.I'm pretty sure Michael Abrash (another id employee) wrote that book.Let us begin with a quick introduction to C. Our aim is to show the essential elements of the language in real programs, but without getting bogged down in details, rules, and exceptions. At this point, we are not trying to be complete or even precise (save that the examples are meant to be correct). These are the first lines of The C Programming Language. I don't claim to be an expert on C (in fact, the reason I was able to quote that so fast was because I have the book opened up next to me, as I'm attempting to improve my knowledge of C), but it seems like Zed is attempting to stir up controversy for no good reason. The book never seemed to me to be an end all be all guide to C, and I don't think most people think of it that way. It's a way for people to get up to speed on the main aspects of the language quickly and without confusion. The book is more about the language itself than about writing in the language. That probably sounds stupid, but IMHO, those are two completely different things. EDIT: Also, I'd certainly be interested in seeing Zed (or anyone for that matter) provide a few examples from the book in a robustified form which would be welcome in a well-written and secure codebase.What part of Zed's deconstruction of K&R has anything to do with Rails?Nothing, it just seems there's a lot of reflexive denunciations whenever something he wrote makes its way to reddit.Zed's writing style is intended to provoke that sort of reaction, he likes to poke trolls with a stick for fun.He's smart but he's a dick. Life is not a copy of "House" and he speaks like he thinks he's the next Issac Newton or Turing. He may be smart, but he's def not smart enough to be an ass all the time as is his want.Zed's clear purpose was not to show that the book is useless or say that it should not be used in education, but to break the misconception that the book is unquestionable, and show that it is not the be all and end all of learning how to code C in the modern industryZed Shaw, the Richard Dawkins of Programming. ;)© 2012 reddit inc. All rights reserved.
Dawkins って無神論者の人だっけ?
しかし Zed のこのシリーズ読んでみたくなったな。 完成しているものを買ってみるか。
今回のテーマは「わたしがプログラマという職業を選んだ理由」で、実は1行で書こうと思えば書けるんですけど、それだとかなり意味不明になってしまって、ちゃんとわかるように書こうとするとやたら長くなります。
sharは,昔のテキストベースなやりとり(ネットニュースとか?)で使われていたらしい.man sharがネットワーク帯域と マシンスペックを異様に気にしていたりするし*1.そのあたりの歴史的背景がよく判っていないのでちょっと曖昧.echoとsedだけで 展開できるのが強みらしいので,アーカイバが無い状況(組み込みとか?)でも使うのかも.
周回遅れ感
一つ前へ
2012年1月(上旬)
一つ後へ
2012年1月(下旬)
リンクはご自由にどうぞ
メールの宛先はこちら

![[標準] C言語重要用語解説 <ANSI C/ISO C99対応>](http://ecx.images-amazon.com/images/I/51OtDwe8PaL._SL160_.jpg)