■_
インタプリタ本読んでる余裕もない。
一つ前へ
2012年2月(上旬)
一つ後へ
2012年2月(下旬)
インタプリタ本読んでる余裕もない。
Mikado == 帝?
InfoQ: Mikado Method For Refactoring Legacy Software The Mikado method proposes a simple solution. For each change, once you find the dependencies that show errors once you make that change, create a graph that depicts these errors, along with what needs to be done to fix them proactively before actually making the change. Then you revert your change and start looking at one leaf in that graph. Fix that error, see if that causes more problems – if it does, repeat the process – continue drawing more leaves on the graph with details of what else needs to be changed, revert the entire code change, and start working on the leaf again.
よくわからんw
鳥取城落城で一区切り。
【ヤングマガジン】センゴク 宮下英樹・62番槍【休載も有るよ】 871 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 05:14:00.95 ID:XczH+Scg0 Be: 宮下先生、秀吉を正当化するために信孝を暗愚に書くのだけはやめてほしいっす。 どうも信忠がエリートっぽいからイケイケに描かれそうなんだよなぁw信雄はどうでもいいけど。 872 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 05:39:16.61 ID:mgSLbyh80 Be: twitterによると次回は鳥取城編ラストだそうだ 873 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 06:30:31.42 ID:YDH4UXJv0 Be: 外伝では、信長を正当化するためか、信広(信長の長兄)は、ちょっと使えなさそうな人に書いてあるな。 実際にも能力的にはイマイチな人だろうけど、誠実な人の感もある。 874 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 06:49:11.10 ID:bNKeeZ3A0 Be: 次号予告。鳥取城編ラスト。 (単行本派かつ史実も知らない方は写真のサブタイトルにネタバレ含んでるゆえ閲覧注意)… あと大戦広報の方すみません。 異業種間の外交だけにネタバレの手前勝手な線引きに以後気をつけます。 (;`宮´)ゞ ttp://pic.twitter.com/xsCeJyZR 880 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 13:24:26.11 ID:Cjb5+DDP0 Be: >>873 糞マジメだけが取り柄って平時でなきゃ使い道無いもん 881 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 13:29:49.88 ID:4oTWgFbm0 Be: >>880 毛利隆元「……」 885 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 15:45:39.57 ID:i7RWpR3T0 Be: >>881 あんた自虐的なだけで実は超有能だったことが死後判明した人じゃないか 886 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 15:49:20.18 ID:7wrmPRE+0 Be: >>885 なんせ、元就ですら死ぬまでその有能さに気が付かなかったらしいから仕方がない びっくりするよなあ、いくら当主とはいえ一人死んだだけで あんな巨大国家が回らなくなるんだもん 887 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 16:21:28.62 ID:HE+oYtvX0 Be: 毛利隆元の死は毛利家だけの銭が回らなくなったが 大内義隆の死は日本全体の銭が回らなくなったという 地味に見える人でも経済の中枢を握っていれば死んだときの周りへの影響力は大きいということですね 888 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 16:25:21.89 ID:ZvT9lDIA0 Be: 当主後継者の準備ができる前に当主が死んだら回らなくなるのは 戦国だと普通じゃね? 889 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 16:27:07.98 ID:i7RWpR3T0 Be: 義隆は晩年プチ引きこもったとはいえ、日本経済の大動脈を押さえる西国一の大大名だったからねえ 大寧寺の変は天文当時としちゃ本能寺の変並みのインパクトはあったろうと思うよ 890 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 16:31:36.34 ID:7wrmPRE+0 Be: >>888 隆元の場合は、周りも本人も事実上当主は元就だと思われてたのが異質 いくら当主ったって、信長が生きてるのに 信忠が死んでも織田家はびくともしないと思うだろ? 桶狭間で信長じゃなく、信忠だけが死んだのに、 配下は片っ端から離反するわ、カネはいきなりなくなるわ 勝ちまくってた戦にバタバタ負けるわ・・ となる様を思い浮かべればわかりやすい 891 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 17:51:31.03 ID:6dMYDgyg0 Be: >>890 笑点で例えると歌丸が司会者で 周りも仕切っているのは歌丸だと思っていたが、 山田隆夫が死んだら番組が回らなくなったって事か。 892 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 17:53:34.30 ID:7wrmPRE+0 Be: >>891 それはおかしい 笑点を支えてるのは、現実に山田隆夫だろ 893 名無しんぼ@お腹いっぱい [] 2012/02/19(日) 18:18:04.21 ID:wjt+09jtO Be: 山田座布団輔隆夫 894 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 18:22:13.35 ID:kHPAfd8SO Be: 史上最も座布団を運び、落語家を突き飛ばした男 895 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 18:28:10.45 ID:HE+oYtvX0 Be: 山田くん座布団全部鳥取城に運んであげて 896 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 18:30:50.85 ID:hpcA+6M20 Be: 隆元みたいなのが今の日本のトップにふさわしいのに ノブやヒデや家康もしくは元就かといって イットも追えずな惨状 リーダーシップが虚勢を張るといった 陳腐さとかもう 897 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 18:33:32.98 ID:9mlRHOleP Be: >>895 そこは重湯とお粥で 898 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 18:41:04.59 ID:GzsA4S/O0 Be: >>890 毛利隆元がそれだけ凄いステルス大名だったってことだな 899 名無しんぼ@お腹いっぱい [sage] 2012/02/19(日) 19:20:40.82 ID:Dvi5WJeu0 Be: タッカリーン…
C言語で仮想関数テーブル(VTBL)を用いて以下のクラスを実装する。
まず、メディアの中に身を投げれば流れがわかる。いま泳ぎやすい場所がわかる。
今日も今日とて Tokyo.Lang.R #0 : ATND に参加。 宿題つきw
↑の帰りに池袋のジュンク堂にいってあれやらこれやら購入。

紹介されている本にも興味があるけれど
紹介者の文章が結構面白い。arton さんのとか。
10年後も世界で通じるために - Nothing ventured, nothing gained. Takuya Oikawa - Google+ - 木曜日と金曜日に通称デブサミ、Developers Summit… Makoto Anjo - Google+ - 木曜日と金曜日に通称デブサミ、Developers Summit…
なんやら伸びていたのでチェック。 Why we created julia - a new programming language for a fresh approach to technical computing : programming The Julia Language
訳は…あとで
The Julia Language The Julia Language Julia is a high-level, high-performance dynamic programming language for technical computing, with syntax that is familiar to users of other technical computing environments. It provides a sophisticated compiler, distributed parallel execution, numerical accuracy, and an extensive mathematical function library. The library, mostly written in Julia itself, also integrates mature, best-of-breed C and Fortran libraries for linear algebra, random number generation, FFTs, and string processing. More libraries continue to be added over time. Julia programs are organized around defining functions, and overloading them for different combinations of argument types (which can also be user-defined). For a more in-depth discussion of the rationale and advantages of Julia over other systems, see the following highlights or read the introduction in the online manual. High-Performance JIT Compiler Julia's LLVM-based just-in-time (JIT) compiler combined with the language's design allow it to approach and often match the performance of C/C++. To get a sense of relative performance of Julia compared to other languages that can or could be used for numerical and scientific computing, we've written a small set of micro-benchmarks in a variety of languages. The source code for the various implementations can be found here: C++, Julia, Python, Matlab/Octave, R, and JavaScript. We encourage you to skim the code to get a sense for how easy or difficult numerical programming in each language is. The following micro-benchmark results are from a MacBook Pro with a 2.53GHz Intel Core 2 Duo CPU and 8GB of 1066MHz DDR3 RAM: C++ (GCC) Julia NumPy Matlab Octave R JavaScript 4.2.1* 7183d97a 1.5.1 R2011a 3.4 2.9.0 V8 3.6.6.11 fib 0.200 1.97 30.74 1360.47 2463.97 334.94 1.48 parse_int 0.242 1.22 16.49 827.13 6871.04 1082.67 2.14 quicksort 0.416 1.25 61.73 135.51 3357.78 971.06 6.66 mandel 0.249 7.15 31.98 66.27 870.55 253.10 6.03 pi_sum 53.524 0.74 18.77 1.09 356.08 269.19 0.74 rand_mat_stat 7.347 3.94 40.98 12.20 57.39 32.39 8.30 rand_mat_mul 227.331 1.01 1.20 0.78 1.69 2.65 291.83 Figure: C++ numbers are absolute benchmark times in milliseconds; (略)
んで、なぜ新言語を作ったのかという理由がこちら
…facial hair ってナニ? Facial hair - Wikipedia, the free encyclopedia
Why We Created Julia The Julia Blog Why We Created Julia 14 Feb 2012 | Viral Shah, Jeff Bezanson, Stefan Karpinski, Alan Edelman In short, because we are greedy. We are power Matlab users. Some of us are Lisp hackers. Some are Pythonistas, others Rubyists, still others Perl hackers. There are those of us who used Mathematica before we could grow facial hair. There are those who still can't grow facial hair. We've generated more R plots than any sane person should. C is our desert island programming language. わたしたちは Matlab の power user です。中には Lisp ハッカーも何人かいます。 Pythonista の人たちもいますし、Rubyist や Perl hacker の人たちもいます。 We love all of these languages; they are wonderful and powerful. For the work we do — scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing — each one is perfect for some aspects of the work and terrible for others. Each one is a trade-off. わたしたちはこういった言語全部が好きです。それらの言語はすばらしく、かつ強力なものです。 わたしたちが行う作業、たとえば科学的コンピューティング、機械学習、データマイニング、 large-scale の線形代数、分散コンピューティングや並列プログラミング といったものの ひとつに対しては完璧であるのに、別のものに対しては terrible なものだったりするのです。 それぞれがトレードオフになっています。 #ダメダメな訳文だ○| ̄|_ We are greedy: we want more. わたしたちは貪欲なのです。もっともっと欲しいのです。 略
そして reddit での反応から
Why we created julia - a new programming language for a fresh approach to technical computing : programming TLDR: We want a language that's open source, with a liberal license. We want the speed of C with the dynamism of Ruby. We want a language that's homoiconic, with true macros like Lisp, but with obvious, familiar mathematical notation like Matlab. We want something as usable for general programming as Python, as easy for statistics as R, as natural for string processing as Perl, as powerful for linear algebra as Matlab, as good at gluing programs together as the shell. Something that is dirt simple to learn, yet keeps the most serious hackers happy. We want it interactive and we want it compiled.These benchmarks are totally bogus. For instance, the c++ version of random matrix multiplication uses the c-bindings to BLAS: they then bemoan "how complicated the code is". This only goes to show that they are not experts in their chosen field: their are numerous BLAS-oriented libraries with convenient syntax that are faster than that binding. For instance, blitz++, which is celebrating its 14th annivesary. The MTL4 is upwards of 10x faster than optimized FORTRAN bindings, and is even faster than Goto DGEMM.Looks very cool! Why PCRE and not the re2 library? re2 lacks back-tracking but does have a linear-time guarentee. I think it would be better suited for scientific computing. If you're really feeling like you have to have it all, support both :-)Only because PCRE is widely used, and some of the regex stuff is pretty core to the language now. I personally did not know about re2, but looks interesting. We should certainly try it out and see how it compares, especially since PCRE now has a jit as well.
どうにも議論が発散しっぱなしな気が。
Mac Book Air (例の略称は使わん) を primary machine として使えるか? という問いかけ
Any developers using latest Macbook Air as primary machine? : ruby Any developers using latest Macbook Air as primary machine? (self.ruby)I am a Ruby and iOS developer. I want to get the latest MBA i7 w/ 256GB SSD. My only problem with it is the 4GB RAM limit, which sucks. I just want to get other's opinions about using the Macbook Air as a main machine for writing code.If the guys at 37signals can do it, so can you.I would advise against it if you're running VMs. I used to have only 4GB on my 13-inch Macbook Pro and it was painful whenever I wanted to run a couple of VMs (using Vagrant/VirtualBox). Maybe wait for the next (Ivy-Bridge based) MB Air? It will probably support adding more RAM (I hope!). If it's not an option, a 13-inch MacBook Pro?
んでまあ、ジュンク堂で買った本の一冊が↓この本なんですが

なんでこう人を挑発するような書きかたしますかね。
例の本に比べればよっぽどおとなしいですが、
こういうところははっきりいってこの人の欠点だと思っています。
前作は一部にわりといいこと書くなあと思った部分もあったのですが
(結局買ってないんですけどね。だから書評も感想も書いてない)、
自分の中で上がりかけた評価が以下略

第6回JVMソースコードリーディングの会(OpenJDK6) - [PARTAKE] に参加しました。濃い話でした。はい。
Gnu Assembler これ以外に、絶対番地へのジャンプ"jmp/call"には、'*'をアドレス値につける。 jmp 0xabcd セッションに対する、相対ジャンプ jmp *0x1234abcd 0x1234abcdへの絶対ジャンプ
*-0xhhhhhhhh(, %ebx, 4) ←これも絶対ジャンプ? AT&T 書式は良くわからんです。
いつにもましてメモがとりとめないなー(ということで封印)
Reddit takes a new direction | Hacker News がだいぶ伸びているので見てみた。
reddit takes a new direction reddit takes a new direction Published February 13, 2012. Filed under: Misc. Several months ago, reddit shook with the news that longtime subreddit /r/jailbait — dedicated to, well, you can probably guess — had been shut down by its own moderators. Yesterday, reddit shook again, with the news that a variety of other subreddits, arranged on similar topical lines, were being shut down by reddit's admins. Predictably, this has caused a shitstorm. It has also caused calls for bans of other subreddits which have nothing to do with sexual fetishes involving children. There are, of course, plenty of subreddits devoted to other deeply disturbing things, and as long as reddit's getting rid of the kiddie diddlers, why not the Nazis and the wife-beaters too? 以下略 Copyright © 2006-2012 James Bennett. All rights reserved. Opinions expressed here are solely those of the author(s).
なんかよくわからんけど、Nazis やら危なそうな単語がちらほら見えるので subreddit /r/jailbait の単語を調べてみたら…なんじゃそりゃあ(^^:
Reddit takes a new direction | Hacker News People tend to think of online communities as democracies where the freedoms they're accustomed to from their normal lives apply. So when a post gets deleted by a moderator, people tend to think of it as a freedom of speech issue. There's a whole constitution out there specifically defending anybody's right to create a pro-Nazi subreddit, and to otherwise post anything they please on the site so long as it's not illegal, right? Not really. Not at all, in fact. Reddit is not the United States. It's Reddit. Online communities are not democracies any more than your back garden is a democracy. You pull weeds, plant seeds, and otherwise encourage the plants in your garden to comport themselves in a manner that ends up with a pleasing result. It's your garden, so you have the absolute right to pull weeds. The weeds get no say. Reddit seems to have forgotten this for a while, and as a result they started sliding until they became, well, Reddit. The community we're currently discussing this in, on the other hand, has been a lot more conscientious in cultivating the type of garden it would like to see. And I think we can all say the result is a lot more pleasant than a less tended place such as Reddit or 4chan.* And I think we can all say the result is a lot more pleasant than a less tended place such as Reddit or 4chan.* I am honestly not sure we can say that at all. I thoroughly enjoy both hn and reddit, for completely different reasons. Sure, from a strictly legal standpoint, it isn't censorship or a constitutional issue, but at the same time, the "anything goes" attitude in places like 4chan and reddit allow for a lot of creative gems and interesting discussion. People instinctively recognize that while you may have to schlep thought he muck to find those gems, it is still important to have an "anything goes place". People will feel betrayed when they put time and effort into making the community what it is, and suddenly the rules are changed on them -- all their effort has been co-opted or may be co-opted, for something they don't want. It feels slimy. (yes we are all aware there is no contract or law or whatever, blah blah legalistic point missing, but the decency of it is still in question). All that being said, I also like the curated, well organized topical community of HN, because sometimes I just don't want to wade through the crap, but that occasional preference switch doesn't diminish either form of community building.
というわけでそっち方面のやり取りの応酬でした。はい。
C++ってのはC 込みなんでしょうか? そしてObjective-Cの伸び率のすごいこと(絶対数のグラフでは目立たないけど) Traditional Programming Language Job Trends - February 2012 | Regular Geek 例によって図などは元記事でよろしく。
Traditional Programming Language Job Trends - February 2012 | Regular Geek Traditional Programming Language Job Trends – February 2012 Published in February 10th, 2012 Posted by Rob Diana in Job Trends Once again, it is time for the job trends for traditional programming languages. Just like the most recent trends updates, we are only looking at Java, C++, C#, Objective C, Perl and Visual Basic. This list has stayed fairly stable during the past few updates and I am always looking to see if something else should be added. Please let me know if you think some other language deserves to be in this group. Also, please review some of the other job trends posts to see if your favorite language is already in one of these posts. (略) Finally, here is a review of the relative scaling from Indeed. This provides an interesting trend graph based on job growth: 最後のこれは相対スケールによる review です。 これは job の成長に基づく興味深いトレンドグラフを示しています。 Objective-C continues to grow like a weed, with some minor dips every few months. C# growth is solid, hovering around 100% for the past 3 years. Visual Basic and C++ continue to show no growth. Perl and Java are still showing signs of life, but growing at 25% is not very significant. Objective-C は weed (雑草)のように、数ヶ月ごとに some minor dips の成長を続けています。 #like a weed でなんか意味がありそうな気がしないでもない C#の成長は solid で、過去三年間おおよそ100%付近の値でした。 Visual Basic と C++ は成長していないようです。 Perl と Java は signs of life をまだ見せていますが、25% の成長は very significant (とても目立つ) といったものではありません。 What does all this mean? First, it is clear the iOS development is hot as is all mobile development. It will be interesting to see if Java can get some sustained growth with the rise of Android developmnent. From the trend perspective, Perl should be watched to see if there is a significant decline over the next year. C# will likely continue its growth as a replacement for C++ and as a language for Windows Phone development. Lastly, Visual Basic really looks like it may finally disappear over the next few years. これらすべてが意味するものとはなんでしょうか? 第一に iOS 開発がすべての mobile 開発のように hot であることは明らかです。 Java は Android 開発の広まりとともに安定した成長を得られた場合には注目に値するでしょう。 trend perspective から、Perl は来年以降目だった下降があれば注目したほうがよいでしょう。 C# は C++ の置き換えや、Windows Phone 開発向けの言語としてその成長を続けるでしょう。 最後に Visual Basic ですが、これはこれからの数年でついに消え去るように思われます。 ©2012 Regular Geek Powered by WordPress
名古屋の読書会はどうだったんだろう
ilya-klyuchnikov/tapl-scala - GitHub TAPL in Scala This project is an attempt to port very nice companion code (written by Pierce in OCaml) for the book "Types and Programming Languages" by Benjamin C. Pierce into Scala. Almost all implementations are ported. Not yet ported implementations will be ported soon. Here is the status: (以下略)
やっぱりこういうのもやらないと駄目なんかねえ
第三回
Python Quiz of the Week - #3 : Python Hello everyone ! So the last Python Quiz of the Week can be called a success. I decided this meant you guys like it and I should make a new one this week. As said previously, the idea is to write up some python tips and tricks presented in the form of short exercises. The quizzes are a fun way to learn about the less obvious features of the python interpreter as well as compete for the best explanation or the most elegant solution. Tell me if you think the level is too easy or too hard. 以前言ったように、このアイデアは短い exercise の形でもって python の tips and tricks をいくつか書き上げるためです。出題されるクイズは python インタープリターの あまりはっきりしていない機能について学ぶための fun way (楽しいやり方?) なのです。 #as well as から後ろをどうまとめたものか あなたが出題のレベルが簡単すぎる、あるいは難しすぎると考えているのなら わたしに知らせてください。 Conditional operator substitute 条件演算子を置き換える In other languages one often has access to the following kind of construct, representing a one line boolean switch: 他の言語には、次に示すような一行で boolean switch を表現する類の構造 (construct) へ アクセスするものがしばしば存在しています。 opening_time = (day in WEEKEND) ? 12 : 9 This has the equivalent effect of: これは次のものと同じ効果をもっています: if (day in WEEKEND): opening_time = 12; else: opening_time = 9; The ? is called a conditional operator. It is not available in python. But we can do the following: この ? は条件演算子 (conditional operator) と呼ばれています。 # ? と : で条件演算子じゃないんだろか これは python では使えないのですが、次のような書き方ができます。 >>> print False and 'Good' or 'Bad' 'Bad' >>> print True and 'Good' or 'Bad' 'Good' Using this knowledge, how could you write the function flip_odd_numbers using only one list comprehensions and the boolean keywords seen above. The function should have this behavior: この知識を基に、ひとつのリスト内包と上述の boolean keywords だけを使って flip_odd_number という関数を書いてみてください。 この関数は次のような動作をします >>> print flip_odd_numbers(range(10)) [0, -1, 2, -3, 4, -5, 6, -7, 8, -9]Python has had conditional expressions since 2.5. def flip_odd_numbers(l): return [-x if x%2 else x for x in l]
age +=1, おまえらにはウイッシュリストを公開しておいて欲しいと私は思うから隗より始めているだけなんですよ? - 角谷HTML化計画(2012-02-19)
かくたにさんの主張はうなずけるのだけど、 誕生日にというのが気に入らないので何か機会を見つけてサプライズを狙うとしよう。
決して誰かの誕生日にその人のウイッシュリストから贈ったのに何の反応もなかったのが 何度もあったので嫌気が差したからではない :)
リリースノートの日本語版が出ているので見ると、「1 件のセキュリティ問題 を修正しました。」とだけあって、高度に危険なセキュリティーバグであるが「libpng における整数オーバーフロー」の修正なのである.
スウェーデンのライ麦畑
この週末は
ちょっと変えたらプログラムの実行速度ががた落ち
c++ - Why does changing 0.1f to 0 slow down performance by 10x? - Stack Overflow Why does changing 0.1f to 0 slow down performance by 10x?I was just curious why this bit of code: const float x[16] = { 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6}; const float z[16] = {1.123, 1.234, 1.345, 156.467, 1.578, 1.689, 1.790, 1.812, 1.923, 2.034, 2.145, 2.256, 2.367, 2.478, 2.589, 2.690}; float y[16]; for (int i = 0; i < 16; i++) { y[i] = x[i]; } for (int j = 0; j < 9000000; j++) { for (int i = 0; i < 16; i++) { y[i] *= x[i]; y[i] /= z[i]; y[i] = y[i] + 0.1f; // <-- y[i] = y[i] - 0.1f; // <-- } } runs more than 10 times faster than this bit (identical except where noted): const float x[16] = { 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6}; const float z[16] = {1.123, 1.234, 1.345, 156.467, 1.578, 1.689, 1.790, 1.812, 1.923, 2.034, 2.145, 2.256, 2.367, 2.478, 2.589, 2.690}; float y[16]; for (int i = 0; i < 16; i++) { y[i] = x[i]; } for (int j = 0; j < 9000000; j++) { for (int i = 0; i < 16; i++) { y[i] *= x[i]; y[i] /= z[i]; y[i] = y[i] + 0; // <-- y[i] = y[i] - 0; // <-- } } when compiling with Visual Studio 2010 SP1. (I haven't tested with other compilers.) c++ performance visual-studio-2010 compilation floating-pointDid you look at the generated assembly?Welcome to the world of denormalized floating-point! They can wreak havoc on performance!!! Denormal (or subnormal) numbers are kind of a hack to get some extra values very close to zero out of the floating point representation. Operations on denormalized floating-point can be tens to hundreds of times slower than on normalized floating-point. This is because many processors can't handle them directly and must trap and resolve them using microcode. If you print out the numbers after 10,000 iterations, you will see that they have converged to different values depending on whether 0 or 0.1 is used. Here's the test code compiled on x64: int main() { double start = omp_get_wtime(); const float x[16]={1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,2.0,2.1,2.2,2.3,2.4,2.5,2.6}; const float z[16]={1.123,1.234,1.345,156.467,1.578,1.689,1.790,1.812,1.923,2.034,2.145,2.256,2.367,2.478,2.589,2.690}; float y[16]; for(int i=0;i<16;i++) { y[i]=x[i]; } for(int j=0;j<9000000;j++) { for(int i=0;i<16;i++) { y[i]*=x[i]; y[i]/=z[i]; #ifdef FLOATING y[i]=y[i]+0.1f; y[i]=y[i]-0.1f; #else y[i]=y[i]+0; y[i]=y[i]-0; #endif if (j > 10000) cout << y[i] << " "; } if (j > 10000) cout << endl; } double end = omp_get_wtime(); cout << end - start << endl; system("pause"); return 0; } Output: #define FLOATING 1.78814e-007 1.3411e-007 1.04308e-007 0 7.45058e-008 6.70552e-008 6.70552e-008 5.58794e-007 3.05474e-007 2.16067e-007 1.71363e-007 1.49012e-007 1.2666e-007 1.11759e-007 1.04308e-007 1.04308e-007 1.78814e-007 1.3411e-007 1.04308e-007 0 7.45058e-008 6.70552e-008 6.70552e-008 5.58794e-007 3.05474e-007 2.16067e-007 1.71363e-007 1.49012e-007 1.2666e-007 1.11759e-007 1.04308e-007 1.04308e-007 //#define FLOATING 6.30584e-044 3.92364e-044 3.08286e-044 0 1.82169e-044 1.54143e-044 2.10195e-044 2.46842e-029 7.56701e-044 4.06377e-044 3.92364e-044 3.22299e-044 3.08286e-044 2.66247e-044 2.66247e-044 2.24208e-044 6.30584e-044 3.92364e-044 3.08286e-044 0 1.82169e-044 1.54143e-044 2.10195e-044 2.45208e-029 7.56701e-044 4.06377e-044 3.92364e-044 3.22299e-044 3.08286e-044 2.66247e-044 2.66247e-044 2.24208e-044 Note how in the second run the numbers are very close to zero. Denormalized numbers are generally rare and thus most processors don't try to handle them efficiently. To demonstrate that this has everything to do with denormalized numbers, if we flush denormals to zero by adding this to the start of the code: _MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON); Then the version with 0 is no longer 10x slower and actually becomes faster. (This requires that the code be compiled with SSE enabled.) This means that rather than using these weird lower precision almost-zero values, we just round to zero instead. Timings: Core i7 920 @ 3.5 GHz: // Don't flush denormals to zero. 0.1f: 0.564067 0 : 26.7669 // Flush denormals to zero. 0.1f: 0.587117 0 : 0.341406 In the end, this really has nothing to do with whether it's an integer or floating-point. The 0 or 0.1f is converted/stored into a register outside of both loops. So that has no effect on performance.Using gcc and applying a diff to the generated assembly yields only this difference: 73c68,69 < movss LCPI1_0(%rip), %xmm1 --- > movabsq $0, %rcx > cvtsi2ssq %rcx, %xmm1 81d76 < subss %xmm1, %xmm0 The cvtsi2ssq one being 10 times slower indeed. Apparently, the float version uses an xmm register loaded from memory, while the int version converts a real int value 0 to float using the cvtsi2ssq instruction, taking a lot of time. Passing -O3 to gcc doesn't help. (gcc version 4.2.1) (using double instead of float doesn't matter, except that it changes the cvtsi2ssq into a cvtsi2sdq) update some extra tests show that it is not necessarily the cvtsi2ssq instruction. Once eliminated (using a int ai=0;float a=ai; and using a instead of 0), the speed difference remains. So @Mysticial is right, the denormalized floats make the difference. This can be seen by testing values between 0 and 0.1f. The turning point in the above code is approximately at 0.00000000000000000000000000000001, when the loops suddenly takes 10 times as long. update<<1 a small visualisation of this interesting phenomenon: Column 1: a float, divided by 2 for every iteration Column 2: the binary representation of this float Column 3: the time taken to sum this float 1e7 times You can clearly see the exponent (the last 9 bits) change to its lowest value, when denormalization sets in. At that point, simple addition becomes 20 times slower. 0.000000000000000000000000000000000100000004670110: 10111100001101110010000011100000 45 ms 0.000000000000000000000000000000000050000002335055: 10111100001101110010000101100000 43 ms 0.000000000000000000000000000000000025000001167528: 10111100001101110010000001100000 43 ms 0.000000000000000000000000000000000012500000583764: 10111100001101110010000110100000 42 ms 0.000000000000000000000000000000000006250000291882: 10111100001101110010000010100000 48 ms 0.000000000000000000000000000000000003125000145941: 10111100001101110010000100100000 43 ms 0.000000000000000000000000000000000001562500072970: 10111100001101110010000000100000 42 ms 0.000000000000000000000000000000000000781250036485: 10111100001101110010000111000000 42 ms 0.000000000000000000000000000000000000390625018243: 10111100001101110010000011000000 42 ms 0.000000000000000000000000000000000000195312509121: 10111100001101110010000101000000 43 ms 0.000000000000000000000000000000000000097656254561: 10111100001101110010000001000000 42 ms 0.000000000000000000000000000000000000048828127280: 10111100001101110010000110000000 44 ms 0.000000000000000000000000000000000000024414063640: 10111100001101110010000010000000 42 ms 0.000000000000000000000000000000000000012207031820: 10111100001101110010000100000000 42 ms 0.000000000000000000000000000000000000006103515209: 01111000011011100100001000000000 789 ms 0.000000000000000000000000000000000000003051757605: 11110000110111001000010000000000 788 ms 0.000000000000000000000000000000000000001525879503: 00010001101110010000100000000000 788 ms 0.000000000000000000000000000000000000000762939751: 00100011011100100001000000000000 795 ms 0.000000000000000000000000000000000000000381469876: 01000110111001000010000000000000 896 ms 0.000000000000000000000000000000000000000190734938: 10001101110010000100000000000000 813 ms 0.000000000000000000000000000000000000000095366768: 00011011100100001000000000000000 798 ms 0.000000000000000000000000000000000000000047683384: 00110111001000010000000000000000 791 ms 0.000000000000000000000000000000000000000023841692: 01101110010000100000000000000000 802 ms 0.000000000000000000000000000000000000000011920846: 11011100100001000000000000000000 809 ms 0.000000000000000000000000000000000000000005961124: 01111001000010000000000000000000 795 ms 0.000000000000000000000000000000000000000002980562: 11110010000100000000000000000000 835 ms 0.000000000000000000000000000000000000000001490982: 00010100001000000000000000000000 864 ms 0.000000000000000000000000000000000000000000745491: 00101000010000000000000000000000 915 ms 0.000000000000000000000000000000000000000000372745: 01010000100000000000000000000000 918 ms 0.000000000000000000000000000000000000000000186373: 10100001000000000000000000000000 881 ms 0.000000000000000000000000000000000000000000092486: 01000010000000000000000000000000 857 ms 0.000000000000000000000000000000000000000000046243: 10000100000000000000000000000000 861 ms 0.000000000000000000000000000000000000000000022421: 00001000000000000000000000000000 855 ms 0.000000000000000000000000000000000000000000011210: 00010000000000000000000000000000 887 ms 0.000000000000000000000000000000000000000000005605: 00100000000000000000000000000000 799 ms 0.000000000000000000000000000000000000000000002803: 01000000000000000000000000000000 828 ms 0.000000000000000000000000000000000000000000001401: 10000000000000000000000000000000 815 ms 0.000000000000000000000000000000000000000000000000: 00000000000000000000000000000000 42 ms 0.000000000000000000000000000000000000000000000000: 00000000000000000000000000000000 42 ms 0.000000000000000000000000000000000000000000000000: 00000000000000000000000000000000 44 ms
なぜこっち (redit) でもこんなに盛り上がるんだろう
Why does changing 0.1f to 0 slow down performance by 10x? : programming Why does changing 0.1f to 0 slow down performance by 10x? (stackoverflow.com)Here's my take on explaining denormals (from this thread): Suppose that you have a notecard with enough space to write 7 digits. You want to represent numbers both large and small in those 7 digits, but obviously it takes more than 7 digits to write 0.00000042 or 420000000. You instead come up with a scheme that you will express all numbers in scientific notation, always starting with "0.", i.e. 0.nnnnn x 10^ee The five n's and two e's will be the things you write on the card, everything else is assumed. Except you want to be able to write negative and positive exponents, and there's no room on the card for that, so you just say that you'll split the range in half and add 50, so if you write 00 on the card that means the exponent was -50, and if you write 99 on the card that means the exponent was 49. You can now happily express the numbers above as 0.00000042 = 0.42000 x 10^-6 = 4200044 420000000 = 0.42000 x 10^9 = 4200059 This works pretty well -- we don't have infinite precision, but we do have 5 significant digits no matter what order of magnitude the number is in. But now suppose you're doing a calculation and an intermediate result is something very small like 0.12345 x 10-50 . And then suppose that for the final answer this must be divided by ten. Okay, that's easy, it's just 0.12345 x 10-51 which encodes as... shit. We can't represent a -51 exponent, so I guess we're hosed, we should throw a fp exception and let software deal with it because this is too edge-casey for our CPU to deal with. We do have an option, though. At the expense of one less significant digit we can choose to represent this number as 0.12345 x 10^-51 = 0.01234 x 10^-50 = 0123400 That's kind of odd, as we shouldn't ever expect to see the first digit on our card as zero, so that should alert us that something went wrong. And we lost a digit of precision, which means that if this was really just an intermediate result (e.g. "n / 10 * 562" and this value is the result of n / 10) then when we multiply next and get back into the representable range, that precision that we lost will be gone forever. Even if the result ends up as a normal number, we can only trust up to four digits (and possibly less) rather than the usual five that we'd expect. This can happen for either positive or negative values (which we didn't represent on the notecard, but assume there's room to put a dot that indicates the presence of a negative sign; I know, it's inconsistent because we said earlier there wasn't room, but that's how IEEE 754 actually works), so the denormals are values that straggle zero on either side. Note that there is of course a gap of unrepresentable numbers immediately around zero, followed by the denormals, followed by the normals (as you expand out from zero in either direction.)
How the Boehm Garbage Collector Works | discontinuously.com How the Boehm Garbage Collector Works The Boehm garbage collector is used by a wide variety of C and C++ programs, and is also used in a number of other language implementations such as D and the GNU Compiler for Java. This article aims to give a high-level overview of how this GC works. Boehm のガーベジコレクターはCやC++で書かれているプログラムで広く使われています。 また、D や GNU Compiler for Java のような他の言語実装の多くにおいても使われています。 本 article ではこのGCがどのように動作しているのかの overview を与えることを目指します。 Why the Boehm GC is Special Boehm GC はなぜ特別なのか Most garbage collectors require the cooperation of the programming language or runtime environment to work. They need to identify allocated memory that is no longer reachable from the current program instruction. One common strategy is to follow a trail of pointers – any object that is currently in scope is considered to be reachable, as are any of the other objects that it contains pointers to. The in-scope objects are known as the root set, and by following the pointer trail we can construct our ‘forest' of reachable memory. Everything else is garbage and will be cleaned up (Figure 1). This approach, however, means that the garbage collector needs to know which pieces of data are pointers and which are plain data. 大部分のガーベジコレクターは、それが動作するのにプログラミング言語かあるいは実行時環境 が協調することを要求しています。ガーベジコレクターは割り付けられたメモリーで current program instruction からもはや到達することのないものを indentify しなければなりません。 (ガーベジコレクターがおこなうあれやらこれやら) それ以外のものすべてはごみであり、clean up されます (Figure 1)。このアプローチはしかし、 データの塊がポインターなのか plain data なのかをガーベジコレクターが理解する必要があり ます。 Figure 1: The set of reachable memory. (Image taken from the Mono project's documentation.) This strategy works easily in ‘cooperative' languages like Java – the runtime environment keeps track of the types of the objects and knows which of their properties are pointers to other objects. However, in ‘uncooperative' languages like C and C++, there is no good way to distinguish pointers from plain data. Pointers are treated as plain integers that we can do arithmetic upon, and plain integers can easily be cast to pointers and used to address memory. Moreover, there are restrictions on how data is laid out in memory; C array elements are guaranteed to be stored contiguously, and C programs often rely on the way that structs are laid out in memory (even though this is not guaranteed as part of the language spec). Storing metadata on the objects to keep track of their types would modify this memory layout. Moreover, it would be a considerable memory and computational overhead to keep track of all these types at runtime. More importantly, most compilers do not provide an easy way to retrieve this type data or to modify the object layout, and even if they did, such changes break binary compatibility and would prevent the program from being linked against libraries that were compiled in the ‘usual' way. この戦略は Java のような、実行時環境が」オブジェクトの型を track し続けていてさらにそ の属性が他のオブジェクトへのポインターかどうかを知っている ‘cooperative' languages では works easily です。しかし、C や C++ のような ‘uncooperative' languages では、ポ インターと plain data を区別するための good way はありません。ポインターは算術演算が可 能な plain integers のように扱われますし、plain integers はポインターへとキャストして アドレスメモリーとして使うことが簡単にできます。 それに加えて、データがメモリ上でどのように配置されているかについての制限があります。 C の配列要素は連続して格納されていることが保証されていますし、 C プログラムはしばしば構造体のメモリ上におけるレイアウトに依存することが (それが言語仕様の一部として保証されてはいないにもかかわらず)しばしばあります。 型を記録し続けるためにオブジェクトにメタデータを格納すると、メモリーレイアウトを変えて しまうでしょう。さらに、実行時にこれらの型すべてを記録し続けるにはメモリー的にも computational 的にも無視しがたいオーバーヘッドがあります。より重要なのは、大部分のコン パイラーは、型のデータを retrieve するためだとかオブジェクトのレイアウトを修正するため の簡単な手法を提供していないということです。仮にそういったものを提供していたとしても、 そういった変更はバイナリ互換性を壊してしまい、“通常の”方法でコンパイルされたライブラ リにリンクすることを阻害してしまいます。 Despite these challenges, the Boehm GC is able to function without any cooperation from the compiler or the runtime environment. In C, the only adjustment one needs to make is to redirect calls to stdlib's malloc()/free() to equivalent ones supplied by the Boehm GC. Let us examine how it achieves this feat. こういった challenges にも関わらず、Boehm GC はコンパイラーや実行時環境からの協力が 一切なくても動作することが可能です。C の場合、 the only adjustment one needs to make は stdlib の malloc()/free() の呼び出しを等価な ones supplied by the Boehm GC に置き換えることです。 Let us examine how it achieves this feat. Chunks and Metadata チャンクとメタデータ The Boehm GC manages metadata by housing all allocated objects within ‘chunks' of memory. These chunks can store one or more objects of equal size, and their headers contain several pieces of metadata, such as the indices of the contained objects that are in use; type information is not included for the reasons outlined earlier. The objects themselves are metadata-free. The GC also maintains a list of addresses of allocated chunks. These chunks are all aligned on a power-of-two boundary, so given a pointer to an object, we can calculate its chunk address simply by masking its low-order bits. Boehm GC は ‘chunks' of memory 中に割り当てられたオブジェクトすべてを housing するこ とによってメタデータを管理します。そのような chunks はひとつのオブジェクトか等しい大き さの複数のオブジェクトを格納できて、そのヘッダーはその chunk に含まれていて使われてい るオブジェクトの添え字のようなメタデータの several pieces を含んでいます。 前述の理由により型情報は含まれていません。 オブジェクトそれ自身は metadata-free です。 GC もまた allocated chunks のアドレスのリストを maintains します。 そういった chunks はすべて二の巾乗の境界にアラインされているので あるオブジェクトへのポインターが与えられたときにその 下位ビットをマスクすることで簡単に chunk のアドレスを計算できます。 Identifying Pointers in Data データ中のポインターを見つけ出す 略 Garbage Collector as Leak Detector Leak Detector としてのガーベジコレクター Although the Boehm GC adds less overhead than other collectors, the marking and sweeping process is still an additional cost that is unacceptable for some applications. However, the Boehm GC is still useful here – it can be used during development to identify leaks! We can drop the Boehm GC into a program that is designed manage memory manually. If it succeeds in finding unused memory to collect, then we know that we have caught a leak. Boehm GC は他のガーベジコレクターよりもオーバーヘッドが少ないのですが、マーキングや sweeping のプロセスには一部のアプリケーションでは許容できない付加コストがあります しかしそれでも依然として Boehm GC は有用です - it can be used during development to identify leaks! We can drop the Boehm GC into a program that is designed manage memory manually. If it succeeds in finding unused memory to collect, then we know that we have caught a leak. Performance Improvements 性能の向上 The current implementation of the Boehm GC is both concurrent and generational, which further improves its performance. I will write about the architecture of those aspects in a follow-up article. If you've read this far, you should follow my RSS feed.
右のカラムにある記事はあまり訳されていない気が (動画もあるしねえ)
InfoQ: Interview and Book Review: The CERT Oracle Secure Coding Standard for Java Interview and Book Review: The CERT Oracle Secure Coding Standard for Java Posted by Srini Penchikala on Feb 15, 2012 The CERT Oracle Secure Coding Standard for Java book covers the rules for secure coding using the Java programming language and its libraries with the goal to help Java developers eliminate insecure coding practices that can lead to vulnerable code. CERT Oracle Secure Coding Standard for Java は、プログラミング言語 Java とそのライブラリを 使った secure コーディングの規則をカバーして Java developer が脆弱性のあるコードに つながるような insecure なコーディングを取り除くのを助けることを目的とした本です。 In today's hyper-competitive world, later may be too late to adopt Agile development and this Roadmap for Success will help you get started. Download "Agile Development:A Manager's Roadmap for Success" now! In Chapter 1, authors discuss the different areas of application security attacks like injection attacks on SQL, XML, XPath and LDAP related code, leaking sensitive data, Denial of Service (DoS) and Concurrency related security vulnerabilities. For the remaining chapters in the book, each chapter follows the same format, first listing all the rules covered on the specific topic. Authors then provide risk assessment summary for each of these rules with ratings on factors like severity, likelihood, and remediation cost. This makes it a good reference for the application developers on secure design and coding topic. Authors illustrate the security vulnerabilities with code examples of both non-compliant and compliant solutions to show how the secure code differs from the insecure implementation. Some of the secure coding categories discussed in the book include Input Validation and Data Sanitization, Declarations and Initialization, Object Orientation, Locking, Thread APIs, Input Output, Serialization and Platform Security. 著者たちは描写しています セキュリティ上の脆弱性を non-compliant solutions と compliant solutions の両方の コード例でもって 本書で議論されているセキュアなコーディングカテゴリの一部には 入力の検査やデータのサニタイズ、 宣言と初期化、 オブジェクト指向、ロック、スレッドAPI群、 入出力、シリアライゼーションとプラットフォーム InfoQ spoke with book authors Fred Long, Dhruv Mohindra, Robert Seacord, Dean Sutherland, and David Svoboda about the motivation for writing the book, how the security rules discussed in the book compare to other security coding frameworks, InfoQ: What was the main motivation for writing the book? この本を書いた主な動機はなんだったのですか? The primary motivation for this book was to bring together information about common coding errors in Java that can result in exploitable software vulnerabilities and provide information about how to avoid them. この本を書いた根本の動機は、ソフトウェアの脆弱性の exploit につながる可能性のある Java における一般的なコーディングエラーに関する情報をひとつに集め それをどのように避けるのかについての情報を提供しようというものでした。 InfoQ: What is the current state of Java secure programming standards space? Java の secure なプログラミングの標準についての現状はどういったものですか? Oracle developed a set of secure coding guidelines which served as a starting point for this effort. The CERT Oracle Secure Coding Standard for Java is the first comprehensive benchmark set of secure coding rules. Oracle は secure コーディングガイドラインを定めました。 そのガイドラインは served as a starting point for this effort. CERT Oracle Secure Coding Standard for Java は、secure コーディングルールの 最初の comprehensive benchmark set です。 以下略
面白そうな本ではあるな。
The Ten Minute Guide to diff and patch The Ten Minute Guide to diff and patch diff と patch の十分間ガイド Situation one: you are trying to compile a package from source and you discover that somebody has already done the work for you of modifying it slightly to compile on your system. They have made their work available as a "patch", but you're not sure how to make use of it. The answer is that you apply the patch to the original source code with a command line tool called, appropriately, patch. 状況1: あなたはあるパッケージのソースと、誰かが作ったあなたの使っているシステム向けの 修正とを使ってコンパイルしようとしています。 その修正は“パッチ”として作られているものですが、あなたはそれをどう使うのかを 良くわかっていません。 その回答は、オリジナルのソースコードに patch と呼ばれるコマンドラインツールを使って パッチを適用するというものです。 Situation two: you have downloaded the source code to an open source package and after an hour or so of minor edits, you manage to make it compile on your system. You would like to make your work available to other programmers, or to the authors of the package, without redistributing the entire modified package. Now you are in a situation where you need to create a patch of your own, and the tool you need is diff. 状況2: あなたはソースコードをダウンロードして あなたは自分の行った作業の成果を他のプログラマーたちが使えるようにしたいとか、 あるいは修正済みのパッケージ丸ごと再配布することなくすませたいと考えました。 Now you are in a situation where you need to create a patch of your own, and the tool you need is diff. This is a quick guide to diff and patch which will help you in these situations by describing the tools as they are most commonly used. It tells you enough to get started right away. Later, you can learn the ins and outs of diff and patch at your leisure, using the man pages. このドキュメントはガイドです diff と patch の 上記のようなシチュエーションであなたを助けてくれるであろう Applying patches with patch patch を使ってパッチを適用する To apply a patch to a single file, change to the directory where the file is located and call patch: ひとつのファイルにひとつのパッチを適用するのには、対象となるファイルが置かれている ディレクトリに移動して、patch を呼び出します: patch < foo.patch These instructions assume the patch is distributed in unified format, which identifies the file the patch should be applied to. If not, you can specify the file on the command line: これらの instructions はパッチが unified foromat で配布されていることを仮定しています。 このフォーマットはパッチを適用すべきファイルの指定が含まれています。 もし対象のファイルの指定がないのなら、コマンドラインでファイルの指定ができます patch foo.txt < bar.patch Applying patches to entire directories (perhaps the more common case) is similar, but you have to be careful about setting a "p level". What this means is that, within patch files, the files to be patched are identified by path names which may be different now that the files are located on your computer rather than on the computer where the patch was created. The p level instructs patch to ignore parts of the path name so that it can identify the files correctly. Most often a p level of one will work, so you use: パッチをディレクトリ全体に適用すること(こちらのほうがより一般的でしょう)も 単一ファイルのときと同様ですが、“p レベル”の設定を注意深く行わなければなりません。 patch -p1 < baz.patch You should change to the top level source directory before running this command. If a patch level of one does not correctly identify any files to patch, inspect the patch file for file names. If you see a name like このコマンドを実行する前にソースディレクトリのトップレベルに変えておくと良いでしょう。 もしあるパッチレベルでパッチを適用すべきファイルのいずれかを正しく指定しない場合、 ファイル名からパッチファイルを推測します。 次のような名前があっって /users/stephen/package/src/net/http.c and you are working in a directory that contains net/http.c, use net/http.c があるディレクトリで作業していたとすると次のコマンドを使用します patch -p5 < baz.patch In general, count up one for each path separator (slash character) that you remove from the beginning of the path, until what's left is a path that exists in your working directory. The count you reach is the p level. 一般的には、パスの先頭から作業しているディレクトリが残るまで 取り除くパスセパレータひとつごとに1数えます。 その数が p レベルです。 To remove a patch, use the -R flag, ie パッチを取り除くには、-R フラグを使います patch -p5 -R < baz.patch Creating patches with diff diff を使ってパッチを作成する Using diff is simple whether you are working with single files or entire source directories. To create a patch for a single file, use the form: 一つのファイルに対してだとか、ソースディレクトリ丸ごとに対して作業する場合には diff を使うのは簡単です。 単一のファイルに対するパッチを作成するには次のようにします: diff -u original.c new.c > original.patch To create a patch for an entire source tree, make a copy of the tree: ソースツリー全体に対するパッチを作成するにはツリーのコピーを作ります: cp -R original new Make any changes required in the directory new/. Then create a patch with the following command: 必要とされるすべての変更をディレクトリ new/ の下のファイルに行います。 それから以下のコマンドでパッチを作成します。 diff -rupN original/ new/ > original.patch That's all you need to get started with diff and patch. For more information use: man diff man patch Translations This article has been translated and republished in the following languages: Spanish: Guia de 10 minutos de diff y patch Portuguese: O Guia de Dez Minutos de diff e patch
きんどるさん もう新しいのが届いたw 古いの送り返せとかどこにもない (メールにもなかった。と思う)けどいいんだろうか
すべての bash scripters が知っておかねばならないこと
Something all bash scripters need to know (and most of us don't) « Bosker Blog Something all bash scripters need to know (and most of us don't) February 12th, 2012 § 8 Comments Calling all bash users. This is a public service announcement. Here's something you need to know if you want to write bash scripts that work reliably, but you probably don't. Recommendations For script authors: Every bash script that uses the cd command with a relative path needs to call unset CDPATH, or else it may not work correctly. Scripts that don't use cd should probably do it anyway, in case someone puts a cd in later. スクリプト書きに: 相対パスを伴って cd コマンドを使っているすべての bash スクリプトでは CDPATH を unset する必要があります。さもなければそのスクリプトは正しく動かない かもしれません。cd を使っていないスクリプトは誰かがあとで cd を追加する場合があるので やはり uset しておくべきでしょう。 For users: Never export CDPATH from your shell to the environment. If you use CDPATH then set it in your .bashrc file and don't export it, so that it's only set in interactive shells. ユーザーに: シェルから環境に対して CDPATH を export してはいけません。 CDPATH を使うのであれば、それを.bashrc ファイルの中でセットし、 export をしてはいけません。 対話シェルの中でのみ set します。 For the bash implementers: Change bash to ignore the inherited value of CDPATH in shell scripts (as opposed to interactive shells). bash の実装者に: シェルスクリプトにおいて継承された CDPATH の値を無視するように bash を変更してください Update Since I wrote this, thanks to commenters here and on Reddit I've learnt two interesting things: CDPATH is not a bash-specific feature; it's actually specified by POSIX. CDPATH は bash特有の機能ではなく、POSIX で決められているものです You can avoid it in some cases by using cd ./foo, which does not consult CDPATH. But this is not a panacea: it can't easily be used with paths that might be absolute or relative, such as `dirname "$0"`, so I think unsetting CDPATH is still the best way to deal with it. cd ./foo のようにすることで一部のケースにおいては予期せぬ動作を排除できます。 こうすると CDPATH を参照しに行きません。 しかし、これは panacea ではありません。 絶対パスや相対パスと一緒に使うのが簡単ではないのです。 たとえば `dirname "$0"` のように。 ですから、CDPATH を unset してしまうのがこれに対処する最善の方法だと考えています。 What you need to know あなたが知っておかねばならないこと The bash shell has a little-known feature that might occasionally be handy in interactive use, but is never useful in a script and acts as a brutal trap for the unwary scripter. The variable CDPATH can be set to a colon-separated list of directories, and then whenever cd somewhere is called with a relative path the directories in CDPATH are tested in turn to see whether somewhere exists in any of them. If it does, the current working directory is changed to that directory and the fully-qualified path of the new working directory is printed to standard output. bash シェルには、対話的に使用するときには有用なこともあるあまり知られていない機能が ありますが、これはスクリプトでは決して有用なことはありませんし、unwary scripter に とっては brutal trap のように振舞います。 変数 CDPATH にはコロンを区切りとするディレクトリのリストをセットでき、 For example: -bash-3.2$ cd # Change to my home directory -bash-3.2$ mkdir foo /tmp/foo # Create directory "foo" here and in /tmp -bash-3.2$ CDPATH=/tmp:. # Set CDPATH -bash-3.2$ cd foo # Call cd /tmp/foo # cd changes to /tmp/foo, and prints it out Here running cd foo changes to /tmp/foo rather than ~/foo, because /tmp precedes . in the CDPATH. If CDPATH is set in the environment, e.g. exported from a shell, then it may cause the cd command to behave unexpectedly in shell scripts. By the robustness principle users should not export CDPATH and scripts should be written to work even if they do. シェルから export されて CDPATH が環境の中にあったとすると、 それはシェルスクリプトにおいて cd コマンドの予期せざる動作を引き起こします。 robustness principle users によって CDPATH が export されるべきではないし、 スクリプトはたとえ CDPATH が export されている場合でも正しく動くように書かれるべきです。 In case you doubted it, it's very common to see scripting idioms that may not work properly if CDPATH is exported. Even the common cd "$(dirname "$0")" falls into this category. How I discovered this trap (the hard way) どのようにしてこのトラップを見つけたのか I've been writing bash scripts for almost half my life, but it still has the capacity to surprise me. At work we have a library of shell code that is used for things like configuration management across several different projects. Because the library is included as a git submodule in many different projects, and these projects themselves will be installed by different people in different places, the library code can't use a hard-coded path to itself; but sometimes it does need to know where it's installed so that library functions can invoke scripts from the same package. Note that this is a library of functions that will be included into other shell scripts using the source command, so we can't assume we're in "$(dirname "$0")" as a straightforward shell script could. But that's okay, because bash has a special variable $BASH_SOURCE that any function can use to find the filename of the file that function is defined it. So I wrote this: これが、source コマンドを使ってほかのシェルスクリプトに取り込まれるであろう関数の ライブラリであり、シェルスクリプトで straightforward に "$(dirname "$0")" のように使われると仮定はできないことに注意してください。 なぜなら、bash はすべての関数がそれが定義されているファイルのファイル名を見つけるのに使える $BASH_SOURCE という特殊変数を持っているからです。 ですから次のように書けます _mysociety_commonlib_directory() { ( cd "$(dirname "${BASH_SOURCE[0]}")"/.. pwd ) } MYSOCIETY_COMMONLIB_DIR=$(_mysociety_commonlib_directory) which sets $MYSOCIETY_COMMONLIB_DIR to the fully-qualified pathname of the parent directory of the directory this function is in. I was happy with the neatness of this solution, and it worked fine in all my tests. A few days ago, though, a user reported a bug that we eventually traced back to this function. It turned out that the cd command was also printing the name of the directory, and so $MYSOCIETY_COMMONLIB_DIR ended up containing the directory name twice. I can only suppose that the user must have CDPATH set in the environment. But what a nasty trap.
結構長い。
The Big Mud Puddle: Why Concatenative Programming Matters 12 February 2012 Why Concatenative Programming Matters Introduction There doesn't seem to be a good tutorial out there for concatenative programming, so I figured I'd write one, inspired by the classic “Why Functional Programming Matters” by John Hughes. With any luck it will get more people interested in the topic, and give me a URL to hand people when they ask what the heck I'm so excited about. Foremost, there seems to be some disagreement over what the term “concatenative” actually means. This Stack Overflow answer by Norman Ramsey even goes so far as to say: “…it is not useful to use the word ‘concatenative' to describe programming languages. This area appears to be a private playground for Manfred von Thun. There is no real definition of what constitutes a concatenative language, and there is no mature theory underlying the idea of a concatenative language.” 以下略
なんか訳語ついてましたっけ? > Concatenative Programming
Lua開発読本の電子書籍販売のお知らせ +おまけ
隣の人からラムダ式の定義とかモロモロについて語ってもらった。
データの前処理/後処理については R を利用する場合でもPerlなりRubyなりで加工することが多いですので、 それだったら統計部分も同じスクリプトでかけた方が便利じゃないかろうか、Pythonだと割と統計用の道具がそろっているので便利だよーという話でした。
出力が追いつきゃしねえ ○| ̄|_
ちょっと前にどこかで見かけたけど、DHLの配送(受け取る側には)鬼じゃなw 月~金の10:00~17:00か土曜の午前中か宅配ボックスかサービスセンター(東京都江東区)で受け取り かって。
Erlang と BEAM の未来 (The future of Erlang and BEAM)
Dodgy Coder: Coding tricks of game developers Saturday, February 11, 2012 Coding tricks of game developers If you've got any real world programming experience then no doubt at some point you've had to resort to some quick and dirty fix to get a problem solved or a feature implemented while a deadline loomed large. Game developers often experience a horrific "crunch" (also known as a "death march"), which happens in the last few months of a project leading up to the game's release date. Failing to meet the deadline can often mean the project gets cancelled or even worse, you lose your job. So what sort of tricks do they use while they're under the pump, doing 12+ hour per day for weeks on end? Below are some classic anecdotes and tips - many thanks to Brandon Sheffield who originally put together this article on Gamasutra. I have reposted a few of his stories and also added some more from newer sources. I have also linked on each story to the author's home page or blog wherever possible.
おあとは元記事を見てのお楽しみ
Why I love Common Lisp and hate Java, part III – macros « Piece of mine
マクロをネタにどういう比較をするんだろうか。
この辺りは一家言持った人がいると思いますが。
Laurence Tratt: A Proposal for Error Handling The two approaches There are two main approaches to trapping and propagating errors which, to avoid possible ambiguity, I define as follows: あいまいさを排除してエラーをトラップしたり propaggate するのには 大きく二つのアプローチがあります。 それを以下のように定義します Error checking is where functions return a code denoting success or, otherwise, an error; callers check the error code and either ignore it, perform a specific action based on that code, or propagate it to their caller. Error checking does not require any support from language, compiler, or VM; it depends entirely on programmers following the convention. Languages which use this idiom include C. 関数は成功したかエラーかいずれかのコードを返す 呼び出し側はそのエラーコードをチェックするか無視するかする。 エラーコードに応じて特定のアクションを実行するか、あるいはそのコードを 呼び出し元に propagate する Exceptions imply a secondary means of controlling program flow other than function calls and returns. When an exception is raised, this secondary control flow immediately propagates the exception to the functions caller; if a try block exists, the exception can be caught and handled (or rethrown); if no such block exists, the exception continues propagating up the call stack. Exceptions require certain features in the language, and support from both compiler and VM. Languages which use this idiom include Java, Python, and Converge. 例外は、関数の呼び出しと復帰以外の(secondaryな)制御フローを仮定する 例外が発生したときにはこの secondary な制御フローが(例外が発生した)関数の 呼び出し元にその例外を伝える 以下略Copyright © 1995-2012 Laurence Tratt
こう、書くに書けないことがいろいろと以下略
二度目のchatできんどるさんは交換と相成りました。
今回はテキストが貼り付けられているのでとてもありがたい
InfoQ: Attila Szegedi on JVM and GC Performance Tuning at Twitter My name is Charles Humble and I'm here with Attila Szegedi, a software engineer on Twitter's Core System Libraries group. Can you give us some overview of your previous work on Rhino that JavaScript implementation on the JVM? Yes sure. Well, it's been a while that I actively did a lot with Rhino. It came into my focus back in, I think, 2005 or because my previous job, we really needed a good scripting environment and my initial encounter with it was I was basically prodding the then maintainers to port the Apache Cocoon fork which had continuations back into the mainline. (以下略)
会場:調整中(名古屋市内)
寝る
「おまえがゆーな」なことなんですが、 細々としたいろいろな事情が積み重なって、 (更新頻度には関係なく)RSSで情報を取得できないところを読む頻度とか量は以前に比べると かなり少なくなっていますね。 などということをとあるところとあるところを読んで思いました。
"The RedMonk Programming Language Rankings: February 2012 – tecosystems" 回帰直線? からちょっと外れている言語を見ていくとなかなか興味深い
きんどるさん
電話でやり取りを覚悟していたのですが、
今はチャットという手段もあるようです。
ということでノータイムでチャットを選択。
その結果エンジニアリングチームに報告したからちょっと待て。ということに。
Embedded in Academia : How Integers Should Work (In Systems Programming Languages) { 2011 12 04 } How Integers Should Work (In Systems Programming Languages) 整数は(システムプログラミング言語において)どのように振舞うべきか My last post outlined some of the possibilities for integer semantics in programming languages, and asked which option was correct. This post contains my answers. Just to be clear: I want practical solutions, but I'm not very interested by historical issues or backwards compatibility with any existing language, and particularly not with C and C++. わたしの前回のポストでは、プログラミング言語における整数セマンティクスのいくつかの可能性に ついてその概略を述べ、 asked which option was correct 今回のポストではわたしなりの回答を書きます。一点明確にしておきましょう。わたしは practical solutions を望んではいますが、historical issues や既存の言語、特に C や C++ に対する backwards compatibility にはそれほど興味がありません。 We'll start with: まずはここから始めます: Premise 1: Operations on default integer types return the mathematically correct result or else trap. デフォルトの整数型に対する操作は、数学的に正しい結果を返すかさもなければトラップする This is the same premise that as-if infinitely ranged begins with, but we'll perhaps end up with some different consequences. The things I like about this premise are: これは同じ premise です that as-if infinitely ranged begins with, but we'll perhaps end up with some different consequences. この premise でわたしが好きなことは It appears to be consistent with the principle of least astonishment. Since it is somewhat harsh — ruling out many semantics such as 2's complement wraparound, undefined overflow, saturation, etc. — it gives a manageably constrained design space. I just don't like two's complement wraparound. It's never what I want. consistent with the principle of least astonishment であることを明らかにする Since it is somewhat harsh it gives a manageably constrained design space. わたしはただ、manageably constrained design space を与える 2の補数の wraparound や 未定義のオーバーフロー、飽和などなどのような ruling out many semantics が好きではないのです。 それらはわたしが求めるものでは決してありません。 Of course there are specialized domains like DSP that want saturation and crypto codes that want wraparound; there's nothing wrong with having special datatypes to support those semantics. However, we want the type system to make it difficult for those specialized integers to flow into allocation functions, array indices, etc. That sort of thing is the root of a lot of serious bugs in C/C++ applications. もちろん、DSP のように飽和演算を望んだりあるいは暗号化のようにラップアラウンドを望む specialized domains があります。そういったセマンティクスをサポートするための特殊なデータ型を 持つことは間違いではありません。しかしわたしたちは、そのような特殊化された整数を 割り当て関数 (allocation functions) だとか配列の添え字などといったものに使うことを 難しくしてしまう型システムを望んでいます。 特殊化された整数のようなものは、 C や C++ で作られたアプリケーションに存在する 深刻なバグの多くの根本原因 (root) なのです。 Despite the constraints of premise 1, we have considerable design freedom in: premise 1 の制約にも関わらず、 わたしたちには considerable な desing freedom があります When to trap vs. giving a correct result? Do traps occur early (as soon as an overflow happens) or late (when an overflowed value is used inappropriately)? いつトラップするかと正しい結果を与えるか トラップを(オーバーフローが発生したら即座に)早めに行うか それとも遅延させる(オーバーフローした値が不適切な形で使われたとき)か? For high-level languages, and scripting languages in particular, traps should only occur due to resource exhaustion or when an operation has no sensible result, such as divide by zero. In other words, these language should provide arbitrary precision integers by default. 高水準言語、とくにスクリプティング言語に対してはトラップはリソース枯渇が起きた場合か 0 による除算のような、操作が sensible な結果を持たないときにのみ発生すべきものです。言い 換えれば、それらの言語は任意精度の整数をデフォルトで提供すべきなのです。 The tricky case, then, is systems languages — those used for implementing operating systems, virtual machines, embedded systems, etc. It is in these systems where overflows are potentially the most harmful, and also they cannot be finessed by punting to a bignum library. This leads to: tricky case は、オペレーティングシステムやバーチャルマシン、 組み込みシステム等々を実装するのに使われるシステム言語です。 It is in these systems where overflows are potentially the most harmful, and also they cannot be finessed by punting to a bignum library. OS や VM のようなシステムではオーバーフローは潜在的に most harmful なものであり、 bignum ライブラリにパントすることでは finess できません。 このことは次の premise を導きます Premise 2: The default integer types in systems languages are fixed size. システム言語におけるデフォルトの整数型は固定サイズである In other words, overflow traps will occur. These will raise exceptions that terminate the program if uncaught. The rationale for fixed-size integers is that allocating more storage on demand has unacceptable consequences for time and memory predictability. Additionally, the possibility that allocation may happen at nearly arbitrary program points is extraordinarily inconvenient when implementing the lowest levels of a system — interrupt handlers, locks, schedulers, and similar. 言い換えると、捕捉されない場合にはプログラムを終了させる例外を raise するオーバーフロー トラップが発生します。固定サイズの整数のための rationale は 要求よりも多くのストレージを割り当てるので、時間的、memory predictability に受け入れがたい consequences (結果、成り行き) です。 加えて、割り当てがプログラムのほぼ任意の地点で起きうる可能性があることは、 割り込みハンドラー、ロック、スケジューラーのようなシステムの 最もハードウェア寄りの部分 (lowest levels) を実装するときに extraordinarily に不便です Side note: The Go language provides arbitrary precision math at compile time. This is a good thing. Side note: Go という言語はコンパイル時に任意精度の math を提供しますが、これは良いことです。 Overflows in intermediate results are not fun to deal with. For example, check out the first few comments on a PHP bug report I filed a while ago. The code under discussion is: 中間結果におけるオーバーフローは扱うのが楽しいものではありません。たとえば、わたしが少し 前に保存していた PHP のバグリポートにあったコメントの最初のいくつかを確かめてみたところ、 ディスカッションの対象となっていたコードはこういったものでした: result = result * 10 + cursor - '0'; It occurs in an atoi() kind of function. This function — like many atoi functions (if you've written one in C/C++, please go run it under IOC) — executes an integer overflow while parsing 2147483647. The overflow is a bit subtle; the programmer seems to have wanted to write this code: これは atoi() のような関数に現れたものです。この関数は atoi 関数 (if you've written one in C/C++, please go run it under IOC) の多くと同様に 2147483647 を解析したときに整数オーバーフローします。 このオーバーフローは bit subtle で、 プログラマーは次のように書きたかったように思えます result * 10 + (cursor - '0') However, the code actually evaluates as: しかしこのコードは実際には以下のように評価されます: (result * 10 + cursor) - '0' and this overflows. そしてこれはオーバーフローします。 How can we design a language where programmers don't need to worry about transient overflows? It's easy: どのようにすればわたしたちはプログラマーが transient overflow を気にする必要のない 言語を設計できるでしょうか? それは簡単なことです: Premise 3: Expression evaluation always returns the mathematically correct result. Overflow can only occur when the result of an expression is stored into a fixed-size integer type. 式の評価は常に数学的に正しい結果を返す。オーバーフローは式の結果を固定 サイズの整数型に格納するのときにのみ起きる可能性がある This is more or less what Mattias Engdegård said in a comment to the previous post. Clearly, eliminating transient overflows is desirable, but how costly is it? I believe that in most cases, mathematical correctness for intermediate results is free. In a minority of cases math will need to be performed at a wider bitwidth, for example promoting 32-bit operands to 64 bits before performing operations. Are there pathological cases that require arbitrary precision? This depends on what operators are available inside the expression evaluation context. If the language supports a builtin factorial operator and we evaluate y = x!; there's no problem — once the factorial result is larger than can fit into y, we can stop computing and trap. On the other hand, evaluating b = !!(x! % 1000000); is a problem — there's no obvious shortcut in the general case (unless the optimizer is especially smart). We can sidestep this kind of problem by making factorial into a library function that returns a fixed-width integer. このことは Mattias Engdegard が先の投稿のコメントで言っていたことです。transient overflow が desirable なのは明らかですが、それにはどのくらいのコストがかかるのでしょうか? わたしは、大部分 のケースにおいては中間結果のための mathematical correctness はタダ (free)であると確信しています。 minority of case における math はより wide な bitwidth で perform することが必要となるでしょう。 たとえば 32ビットのオペランドは演算を実行する前に64ビットへ昇格します。 さて、arbitrary precision を要求するような pathlogical case は存在するでしょうか? それは evaluation context での式の内側で使える演算子がなんであるかに依存しています。 もしその言語が組み込みの階乗操作をサポートしていて、y = x! を評価したのなら問題はありません。 階乗の結果がyに収まらないほど大きくなったなら計算を止めてトラップできます。 一方で b = !!(x! % 1000000) の評価は問題となります。 (オプティマイザーが特に賢いものである限り) 一般的なケースでは明らかなショートカットはありません。 この種の問題は factorial を固定幅の整数を返すライブラリ関数にすることで sidestep できます。 A consequence of premise 3 that I like is that it reduces the number of program points where math exceptions may be thrown. This makes it easier to debug complex expressions and also gives the optimizer more freedom to rearrange code. わたしが好きな premise 3 の consequence は math 例外が送出される可能性があるときにprogram points の数を縮小することです。 このことは複雑な式のデバッグを容易にし、 また、オプティマイザーに対してより多くのコードを再アレンジする自由を与えます The next question is, should overflows trap early or late? Early trapping — where an exception is thrown as soon as an overflow occurs — is simple and predictable; it may be the right answer for a new language. But let's briefly explore the design of a late-trapping overflow system for integer math. Late trapping makes integers somewhat analogous to pointers in C/C++/Java where there's an explicit null value. 次なる疑問はオーバーフローのトラップは早めに行うか遅延させるかということです。オーバー フローが発生するとすぐに例外が送出される早めのトラップは単純で、予測可能なものです。新 しい言語に対しても(早めのトラップが)おそらく正しい答えであるでしょう。 とはいえ、整数演算のための late-trapping オーバーフローシステムの設計を breiefly に explore してみましょう。 late trapping は整数を explicit な null 値が存在する、 C/C++/Java におけるポインターの ような何かにします。 We require a new signed integer representation that has a NaN (not-a-number) value. NaN is contagious in the sense that any math operation which inputs a NaN produces NaN as its result. Integer NaNs can originate explicitly (e.g., x = iNaN;) and also implicitly due to uninitialized data or when an operation overflows or otherwise incurs a value loss (e.g., a narrowing type cast). わたしたちには NaN 値を備えた新たな符号つき整数表現が必要です。 NaN の入力が NaN を生成するすべての math operation の意味合いにおいて、 NaN は contagious (伝染性、移りやすい) です。 整数の NaN は (たとえば x = iNaN のように) explicitly に originate できるし、 また、未初期化データに対してや ある演算でオーバーフローその他によって値が失われる (たとえば narrow方向へのキャストによって)ことがあったときに implicitly に originate することもできます。 Integer NaN values propagate silently unless they reach certain program operations (array indexing and pointer arithmetic, mainly) or library functions (especially resource allocation). At that point an exception is thrown. 整数の NaN 値は (主に array indexing and pointer arithmetic といった)特定の program operations か、あるいは (特にリソースの割り当てを行う)ライブラリ関数 に reach しない限 り sliently に propagate します。At that point an exception is thrown. The new integer representation is identical to two's complement except that the bit pattern formerly used to represent INT_MIN now represents NaN. This choice has the side effect of eliminating the inconvenient asymmetry where the two's complement INT_MIN is not equal to -INT_MAX. Processor architectures will have to add a family of integer math instructions that properly propagate NaN values and also a collection of addressing modes that trap when an address register contains a NaN. These should be simple ALU hacks. この新しい整数表現はこれまで INT_MIN に使ってきたビットパターンが NaN を表すようになることを 除けば 2の補数と identical なものです。この選択には、 INT_MIN が -INT_MAX と等しくないという 2の補数における inconvenient asymmetry を取り除くという副作用があります。プロセッサーのアー キテクチャは NaN values を適切に propagate する整数算術命令やアドレスレジスターが NaN を保持 しているときにトラップするアドレッシングモードの collection ファミリーを追加しなければならな くなるでしょう。 These should be simple ALU hacks. A few examples: いくつか例を挙げましょう int x; // x gets iNaN char c = 1000; // c gets iNaN cout << iNaN; // prints "iNaN" p = &x + iNaN; // throws exception x = a[iNaN]; // throws exception Good aspects of this design are that an explicit “uninitialized” value for integers would be useful (see here for example), execution would be efficient given hardware support, programs would tolerate certain kinds of benign overflows, and the stupid -INT_MAX thing has always bothered me. It's also possible that a more relaxed overflow system leads to some nice programming idioms. For example, iterating over the full range is awkward in C. But now that we have a sentinel value we can write: この設計の good aspects は、 整数に対する明確な「未初期化」の値が有用で、 実行はハードウェアのサポートを与えられ効率の良いものとなり programs would tolerate certain kinds of benign overflows, and the stupid -INT_MAX thing has always bothered me. プログラムは いくつかの nice なプログラムのイディオムを導くような、より relax なオーバーフローシステムも 可能です。たとえば full range の iterating over は C では awkward ですが、 しかしこれは番兵となる値を持てるので次のように書けるようになります for (x = INT_MIN; x != iNaN; x++) { use (x); } The main disadvantage of late trapping is that it would sometimes mask errors and make debugging more difficult in the same way that null pointers do. Type system support for “valid integers”, analogous to non-null pointers, would mitigate these problems. On the other hand, perhaps we'd have been better off with early trapping. 遅延させたトラップの欠点は、それがときとしてエラーを隠してしまい、ナルポインターが行うのと 同様にデバッグをさらに困難にする可能性があることです。non-null ポインターに類似した “valid integers” のための型システムのサポートはこのような問題を mitigate (沈静する、和らげる) するでしょう。 一方で、おそらくわたしたちは early typing でよりいっそう楽になっているでしょう。 Finally, we could design an integer system using the iNaN integer representation and also early trapping. In this system, iNaN would exclusively be used to represent uninitialized or garbage values. Any operation on iNaN other than simple copying would result in a trap. 結局のところ、わたしたちは iNaN 整数表現と早めのトラップを使った整数システムの設計が可 能です。このシステムでは、iNaN が未初期化値やゴミ (garbage values) を表現するのに exclusively に使われるようになるでしょう。 Any operation on iNaN other than simple copying would result in a trap. iNaN に対する単純なコピー以外の 操作の結果はトラップとなるでしょう Posted by regehr on Sunday, December 4, 2011, at 8:13 am. Filed under Compilers, Software Correctness. Follow any responses to this post with its comments RSS feed. You can post a comment or trackback from your blog.© 2011 John Regehr
だいぶ粗がありますがちと飽きたw
神保町つーてもグランデは理工学書を扱わなくなっちゃったし、 三省堂辺りはそこそこあるけどどんなもんかと。 古書(明倫館書店しか知らんけど)にしても往時に比べるとだいぶ見劣りする気が。
古書はほかでどういうところがいいのかわからんけど、 新刊はジュンク堂じゃないかなあ。今は。 新宿にはわりとどこかの店頭在庫を持ってきたようなのもあったんだよねえ。
推薦図書/必読書のためのスレッド 66 188 デフォルトの名無しさん [sage] 2012/02/12(日) 14:51:52.53 ID: Be: 東京の丸善とか行っても目新しい本が無い。どの棚を見ても習得した物ばかり。 アキバのコンピュータ館1階本屋があったころは面白い本が結構あったのに。 日本のどこかにコンピュータ関係で充実しているいい本屋ありませんか? 189 デフォルトの名無しさん [sage] 2012/02/12(日) 14:53:55.14 ID: Be: ジュンク堂に無ければamazonくらいじゃね 190 デフォルトの名無しさん [] 2012/02/12(日) 16:15:04.08 ID: Be: ステマだー 191 デフォルトの名無しさん [sage] 2012/02/12(日) 16:32:26.50 ID: Be: >>188 神保町へ行け 普通の書店も、古書店も、品揃えは半端ない あそこで探して見つからないなら、ほぼ他では見つからん
第二回。
Python Quiz of the Week - #2 : Python Hi guys ! A while back there was a post called Python Quiz of the Week - #1 which I thought was pretty cool. But I never saw any quiz #2. So, I thought I could prepare some quizzes myself and post them here for those that are interested. The idea would be to write up some python tips and tricks presented in the form of short exercises. A fun way to learn about the less obvious features of the python interpreter as well as compete for the best explanation or the most elegant solution. Maybe the population of /r/python will consider the questions too easy and they might already all know about this. We shall see so with the votes : ) This is my first quiz ! I will post the answer I came up with later in the comments. Advanced list comprehensions In this question we will explore the use of lists comprehensions. List comprehensions are one of the great feature of the python interpreter that you always miss when coding in languages that don't have them. They enable you to build lists using a for loop contained in one line. For those who are not familiar with them, here is how they work: nums = range(6) pairs = [x*2 for x in nums] print pairs >>> [0, 2, 4, 6, 8, 10] You can add a condition inside your list comprehensions: リスト内包の内側に条件を追加できます nums = range(10) odds = [x for x in nums if x%2==1] print odds >>> [1, 3, 5, 7, 9] Of course you can get interesting effects by nesting them: もちろん、リスト内包をネストして面白い効果を得ることもできます nums = range(4) print [a-1 for a in [b*2 for b in nums]] >>> [-1, 1, 3, 5] Using this knowledge, how could you write the function flatten_list using only list comprehensions ? The function should have this behavior: これらの知識を元に、リスト内包だけを使って flatten_list 関数を書けますか? この関数は次のような動作をします: print flatten_list([[1,2,3],[4,5,6],[7,8,9]]) >>> [1, 2, 3, 4, 5, 6, 7, 8, 9] Using this knowledge, how could you write the function make_all_couples using only list comprehensions ? The function should have this behavior: 今回の知識を元にして、リスト内包だけを使って make_all_couples 関数を書けますか? この関数は次のように動作します: print make_all_couples(['a','b','c','d']) >>> [('a', 'a'), ('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'a'), ('b', 'b'), ('b', 'c'), ('b', 'd'), ('c', 'a'), ('c', 'b'), ('c', 'c'), ('c', 'd'), ('d', 'a'), ('d', 'b'), ('d', 'c'), ('d', 'd')] Using this knowledge, how could you write the function parse_ugly_string using only list comprehensions, the split function and the dict function ? The function should have this behavior: リスト内包とsplit 関数、それに dict 関数だけを使って parse_ugly_string 関数を書けますか? この関数は次のような動作をします print parse_ugly_string("a=1,b=2,c=3\nd=4,e=5,f=6\ng=7,h=8,i=9\n") >>> {'a': '1', 'b': '2', 'c': '3', 'd': '4', 'e': '5', 'f': '6', 'g': '7', 'h': '8', 'i': '9'}
再放送は2月17日(木)深夜0時25分-0時50分。
ちょっとグダグダだったりするのも仕方ないと言えば仕方無いのですけれど,当日にも発表資料を作っているというような状況が当たり前のように受け入れられるのは良いのかな,と感じました.
2012年3月10日(土) 午後1時~6時 ※ 毎月1回定期的に開催する予定です。
もっときっちりした話はTAPLの15章あたり参照
(Island Life - simple-vector)
な TAPL の読書会だったのですが、
今回は人数が集まらずに読み進めることはしませんでした。
今日は今日でほかにもいろいろあったようですねえ。
melancholic afternoon
(1) readghc0
ブックカバーを語りましょう
文庫、新書、四六判、A5 あたりはわりと豊富に見つかるんですけど
オライリーでよくあるあのサイズにあうのって結構なかったりしますよね。
化粧カバーひっぺがして持ち歩いてたりしますが、
ちと気になることも。
きんどるさんがぶっこわれました ○| ̄|_
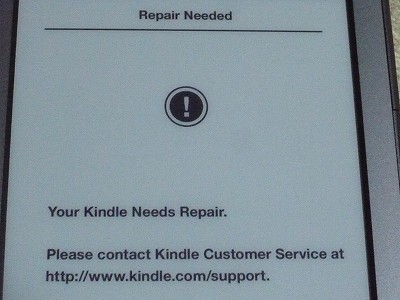
いろいろやってみたのですが、修理(交換?)するよりないようです。 … 電話でやり取りかあ。リスニング自信ねーぞw Amazon.com Help: Troubleshooting Your Kindle
んで、touch が日本からも買えるようになったとか (それでオススメのメールもきた)、日本発売が決まったとかいう話もあるんで さてどうしたものかいなあ。と。 日本発売が事実として、手元にあるこれのサポートを期待なんてのはしてないんですけどね。
Running Python and R inside Emacs — The Endeavour Running Python and R inside Emacs Emacs の内側で Python や R を実行する by John on February 9, 2012 Emacs org-mode lets you manage blocks of source code inside a text file. You can execute these blocks and have the output display in your text file. Or you could export the file, say to HTML or PDF, and show the code and/or the results of executing the code. Here I'll show some of the most basic possibilities. For much more information, see orgmod.org. And for the use of org-mode in research, see A Multi-Language Computing Environment for Literate Programming and Reproducible Research. Source code blocks go between lines of the form ソースコードブロックは次の形式の行の間に置きます #+begin_src #+end_src On the #+begin_src line, specify the programming language. Here I'll demonstrate Python and R, but org-mode currently supports C++, Java, Perl, etc. for a total of 35 languages. #+begin_src の行ではプログラミング言語を指定します。 今回は Python と R を使いますが、org-mode が現在サポートしているものには C++、Java、Perl をはじめとして合計 35言語あります。 Suppose we want to compute √42 using R. R を使って√42を計算したいとしましょう。 #+begin_src R sqrt(42) #+end_src If we put the cursor somewhere in the code block and type C-c C-c, org-mode will add these lines: カーソルがこのコードブロックのどこかにある状態で C-c C-c とタイプすると org-mode は次のような行を追加します: #+results: : 6.48074069840786 Now suppose we do the same with Python: こんどは同じことをPython でやってみましょう: #+begin_src python from math import sqrt sqrt(42) #+end_src This time we get disappointing results: 今回は残念な結果になります: #+results: : None What happened? The org-mode manual explains: 何が起きたのでしょうか? org-modeのマニュアルの説明にはこうあります: … code should be written as if it were the body of such a function. In particular, note that Python does not automatically return a value from a function unless a return statement is present, and so a ‘return' statement will usually be required in Python. コードは関数の本体にあるかのような形で書きましょう。特に、Python が return 文がなければ 関数から値を返すことはないことと、Python を使ったときには 'return' 文が必須になることが 普通であることに注意しましょう。 If we change sqrt(42) to return sqrt(42) then we get the same result that we got when using R. sqrt(42) を return sqrt(42) に変えると R を使ったときと同じ結果が得られます。 By default, evaluating a block of code returns a single result. If you want to see the output as if you were interactively using Python from the REPL, you can add :results output :session following the language name. デフォルトでは、コードのブロックの評価ではひとつの結果が返されます。 もし REPL からPython を対話的に使ったような出力を得たいのなら、 :results output :sesseion を言語名の後ろに付加します #+begin_src python :results output :session print "There are %d hours in a week." % (7*24) 2**10 #+end_src This produces the lines これは次のような結果を生成します #+results: : There are 168 hours in a week. : 1024 Without the :session tag, the second line would not appear because there was no print statement. :session タグがない場合、print 文がないので二行目は現れません。 I had to do a couple things before I could get the examples above to work. First, I had to upgrade org-mode. The version of org-mode that shipped with Emacs 23.3 was quite out of date. Second, the only language you can run by default is Emacs Lisp. You have to turn on support for other languages in your .emacs file. Here's the code to turn on support for Python and R. (org-babel-do-load-languages 'org-babel-load-languages '((python . t) (R . t))) Update: My next post shows how to call code in written in one language from code written in another language.
I am a great programmer, but horrible algorithmist | Hacker News
「アルゴリズマー」よりはしっくりくる表現な気がする > algorithmist
I am a great programmer, but horrible algorithmist - Learning Software Development - The Trendline I am a great programmer, but horrible algorithmist February 10, 2012 by Vic Cherubini — General Ideas I am a great programmer, but a horrible algorithmist. It is a thought that has been weighing on me heavily recently, and I'd like to gather other developers feelings on the subject as well. I started what can be called my professional development career back in 1999. I was still in middle school, but my father hired me at his software company. My official duty was to make updates to our websites, but I mostly ended up bugging the other developers to help me learn. 以下略© 2012 Copyright 2011 - Vic Cherubini
で、たくさんあった反響の中から
I am a great programmer, but horrible algorithmist | Hacker News I am an excellent eater of hamburgers, but a horrible eater of cows. If you can build large scale systems, you can code complex algorithms. It's really just a matter of breaking down your problem into bite size pieces and confronting them one at a time. These days, I'm happy to get my ground beef from the supermarket and my building blocks from repositories, even though I know that I could move multiple levels back up the chain if I really had to.My advice would be to start by practicing small algorithms first, then move on to larger onesAnd by small, I mean small. Not binary-search-sized, even that is too big. Start by giving yourself two functions: "add1" (adds one to a number) and "sub1" (subtracts 1 from a number). Then build normal addition: def add(x, y): if y == 0: return x else: return add(add1(x), sub1(y)) This is a pretty simple algorithm, but it helps to get you in the right frame of mind to figure out larger ones. The Little Schemer series of books is a great (albeit quirky) introduction to stuff like this (and other things too).Sorry, but if you are horrible algorithmist, you are definitely not a great programmer.
なんか最近どこかの英文記事で見たよな >Ada の代わりに C++ で
F-35の開発で生まれたソフト技術 - 組み込みソフト - Tech-On! 一般に航空機の電子制御系ソフトウエアというと、信頼性などを重視して、強い静的型付けという 特性を持つ「Ada」というプログラミング言語が使われることが多いのですが、F-35の設計が始まっ た1990年代後半、 ・Ada言語の最新ハードウエアにおけるツール・サポートが衰退し始めている ・オブジェクト指向で行った設計を、オブジェクト指向をサポートしないプログラミング言語(Ada) の上で実装したくない ・(1990年代後半のドットコム・ブームの中では)若く有望なソフトウエア技術者はAda言語にほと んど興味を示さない といった要因があり、C++が採用されました。
Ada も新しいバージョンで「オブジェクト指向」サポートしてんでなかったっけ? よく知らんけど。 それでも一つ目と三番目の条件は…ねえ。
Perl と PHP ならともかく、Java にもこういう人がでるんか。
不勉強などと切って捨てるのは簡単だけど、なぜそう考えるようになったのかに ちょっとばかし興味がある (どこでどのように教わったんだろうか? いや、まったくの独学?)。
変数を動的に利用するには? | OKWave Javaプログラミングの質問です。 下記のように変数を定義しておき、 String aaa_0 = "AAA1"; String aaa_1 = "AAA2"; 例えば、これらの変数の値を次のようにして使えますでしょうか? (できませんが、やりたいことは、なんとなく伝わったかと思います。) for(int i=0;i<2;i++){ System.out.println("aaa_" + i); } 変数を動的に呼び出せますでしょうか? アドバイスお願い致します。ANo.4 String Array として使用できます。 次を参照ください。 public class zz { public static void main(String[] args) { String saa = "String aa"; String sab = "String ab"; String sac = "String ac"; String sad = "String ad"; String saz = "String az"; String[] straa = {saa,sab,sac,sad}; straa[3] = saz; for(int i = 0; i < 4; i++) System.out.println("straa[" + i + "] = " + straa[i]); } }ANo.2 aaa_0やaaa_1がローカル変数ではなくてフィールド(クラス変数やインスタンス変数)であれば、リフレクションを使ってこんな風に書けます。あまりお勧めはしませんが。 public class X { private String aaa_0 = "AAA1"; private String aaa_1 = "AAA2"; public static void main(String[] args) { X obj = new X(); try { for (int i=0; i<2; i++) { java.lang.reflect.Field f=obj.getClass().getDeclaredField("aaa_"+i); System.out.println(f.get(obj)); } } catch (Exception e) { e.printStackTrace(); } } }Copyright © OKWave. All rights reserved.
回答するほうもそれでいいのかとツッコミ入れたい
例のFORTRANのはなしの続き。 PDFからテキスト抜けたので楽ができるw
FULL TEXT OF ALL QUESTIONS SUBMITTED BOB BEMER How about a word on how long it took Sayre and Goldberg to pick up Best's section when he left? M. A. BREBNER With respect to FORTRAN, what do you consider was the best design decision, and what do you feel was the worst design decision? DAVE DAHM Why did you decide to put the variable being assigned on the left rather than the right of the "=" sign? Where did the idea of the subscripted variable come from originally? BILL DERBY What language was used for your FORTRAN compiler, and how easily did it translate to the 704's successor? KEN DICKEY How were the bounds of your Monte Carlo simulation flow analysis (section 4 of compiler) arrived at (i.e., how did you bound your system)? HAROLD ENGELSOHN In the initial stages of planning, was there any conscious effort to allow for data processing as well as algebraic manipulation? If not, when were alphabetization capabilities, for example, added to FORTRAN?
一つ前へ
2012年2月(上旬)
一つ後へ
2012年2月(下旬)
リンクはご自由にどうぞ
メールの宛先はこちら
